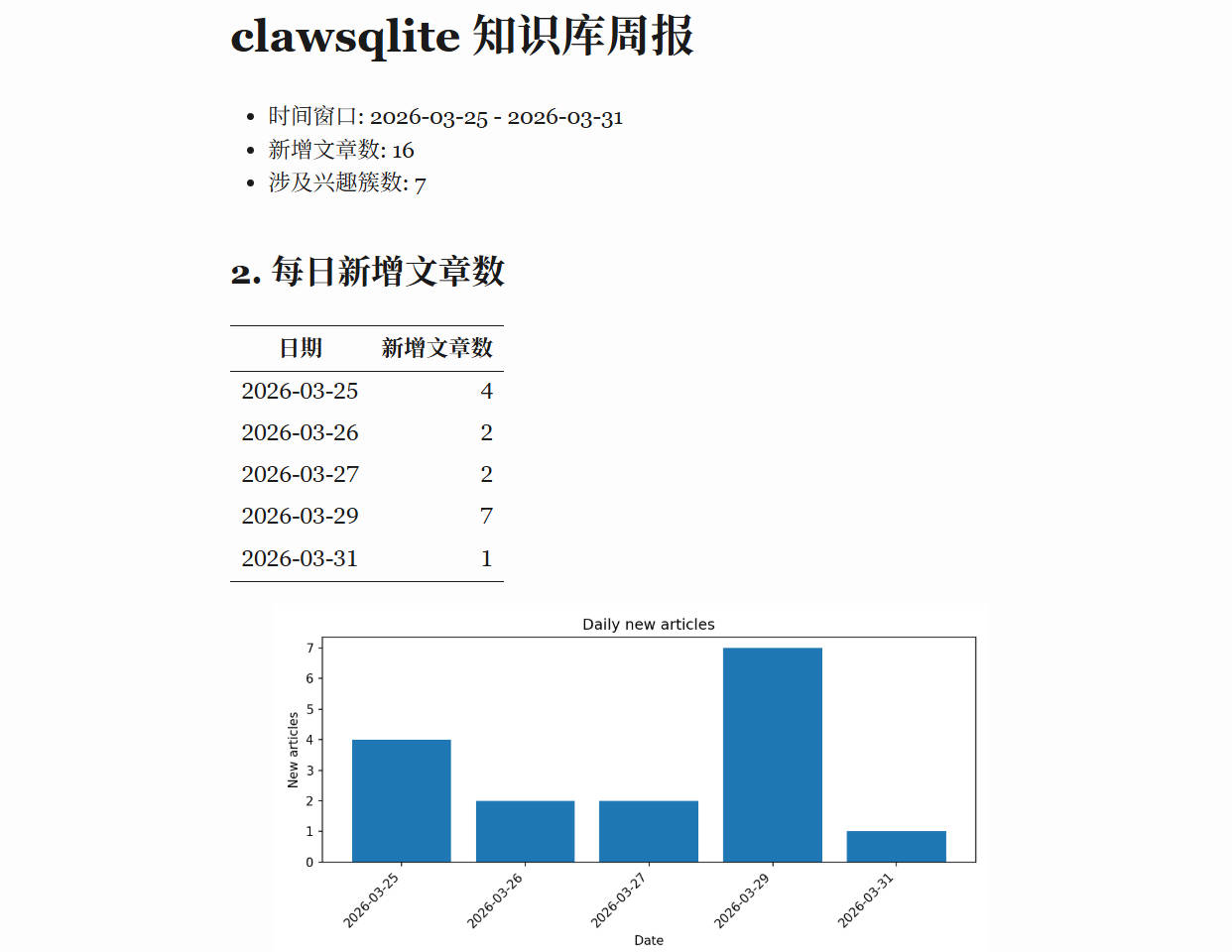
把大象放进冰箱一共三步,从Andrej Karpathy的LLM Wiki聊一聊个人知识库
我的博客封面上写着一句话:In scripts we trust; the rest is up to God。中文大概可以译成:让代码的归代码,其余的归上帝。 这句话不是装腔作势,而是在提醒自己:确定性的事情交给确定性的系统去做;模糊性的事情,才交给模型去发挥。知识库是我们长期积累资料、调用资料、依赖资料的对象。我们今天往里放东西,最好希望三个月后、半年后、一年后,它依然能稳定地把东西找回来,而不是每次都像抽奖。 LLM Wiki很火,但我劝你三思 最近,Andrej Karpathy 介绍他的 LLM Wiki 方法,在网上很火。这个思路确实很吸引人:原始资料是一层,LLM 生成和维护的 wiki 是一层,最上面再来一层 schema 去约束组织方式、命名规则、吸收新内容的流程,以及回答方式。听上去很高级,也很符合现在很多人对 AI 的期待:资料本身不需要太操心,结构会自己长出来,LLM 会替你把中间层收拾好。 我当然很尊敬Andrej Karpathy,也常常听他的播客访谈。但我看完以后,第一反应是:这件事太像“把大象放进冰箱一共三步”了。开门,把大象放进去,关门。说法当然没有错,问题是你真有一头大象时,就会发现根本不是这么回事。冰箱够不够大,门能不能关上,大象会不会挣扎,放进去以后还能不能长期维持,这些真正麻烦的事,全都被“三步”给抹平了。LLM Wiki 也是一样。最迷人也最危险的,恰恰是中间这层由 LLM 持续生成和维护的 wiki。它听上去像智能,实际上意味着漂移、失控和高成本。 今天你加十篇资料,它可能重写三页。明天你换一个模型,摘要口径可能又变。后天上下文再长一点,概念边界和命名体系也跟着漂。这个流程天然很难做到幂等:同一批资料,你跑一次和跑两次,结果未必一样。做 demo、做概念验证、做一次性的专题整理,这当然很酷;但如果你想把它当成自己的长期知识系统,问题就很大。LLM Wiki当然很酷。但是它把最关键的中间表达,交给了最不稳定的LLM输出。你无法完全信任它,将它当成一套长年积累的知识系统。更何况,如果让一个带上下文记忆而且循环的AI Agent处理中间层,每一次从资料内容到Wiki的转换都需要带着数万的上下文和同样数量级的文章发起请求。你原本就不富裕的coding plan一下子就被吸干了。值得吗? 我做 clawsqlite-knowledge,走的是另一条路。不是先让 LLM 给我生成一层很漂亮的 wiki,再希望以后慢慢把它固定住;而是先把底层结构钉牢,让知识库本身是可重复、可扩展、可调参的,再让模型在局部环节帮忙。为了做到这一点,这几天我对 clawsqlite-knowledge 和它底层的clawsqlite · PyPI CLI 做了一轮比较大的算法升级。现在两者都已经到了 v1.0.0。这个 v1,在我看来并不是“功能多了一点”,而是底层思路开始真正成型了。 知识库与幂等性 幂等性这个词听上去有点技术,但意思其实很简单:同一个操作,执行一次和执行很多次,结果应当一样。第一次就把该做的事情做完,后面重复执行,不应当无缘无故改变结果。对数据库、索引、搜索系统来说,这个性质很重要;对知识库来说,更重要。因为知识库不是一次性的输出,而是一个要长期依赖的底座。 LLM Wiki 最大的问题,就在这里。你让 LLM 去处理原始资料,生成中间层 wiki,这一次生成的内容和下一次天然会有差异。这不是它“偶尔失手”,而是它的推理方式决定的。它很擅长生成、概括、改写、重组,但并不天然擅长维持严格一致的中间表达。那在这种前提下,我们怎么把它当成一个长期稳定的知识来源? clawsqlite-knowledge 这次升级,核心其实就是围绕这个问题展开的。我不是想让它“更像一个会说话的 AI”,而是先让它更像一台能重复运行的机器。资料进来以后,先被转换成一组结构化对象:摘要、标签、全文索引、向量索引、兴趣向量、兴趣簇,以及相关的 meta 信息。它们先落库,先固定,后面的搜索、召回、聚类、报告,全部是在复用这套已经落地的结构,而不是每次重新让模型自由发挥。 换句话说,这次不是在给知识库“加更多智能”,而是给它夯实地基。 重构查询入口 这次升级里,最直观的一层改动,是查询入口被彻底重构了。 人类提出问题时,天然是口语的、跳跃的、带噪音的。比如你会说:“我记得之前存过一些跟卫星图、新闻查询、情报收集有关的内容,你帮我找找。”这句话对人类来说很好懂,因为人会自动忽略“我记得”“之前”“帮我找找”这种语气成分,只抓住真正有信息量的部分。对数据库来说就不一样了。数据库不会自动替你做这种收束。它只会拿到一整句原话,然后尽量去匹配。 ...