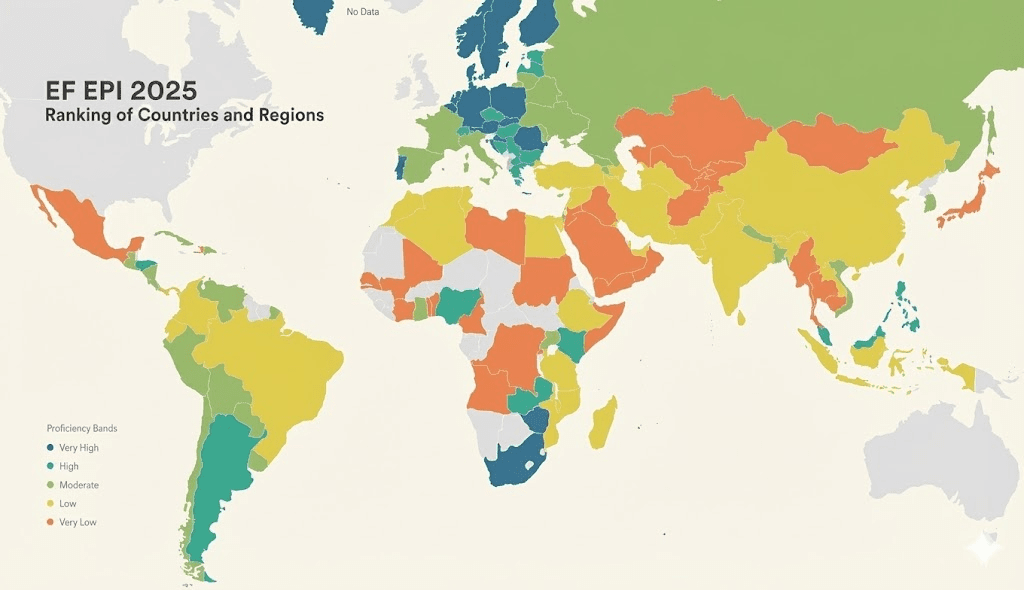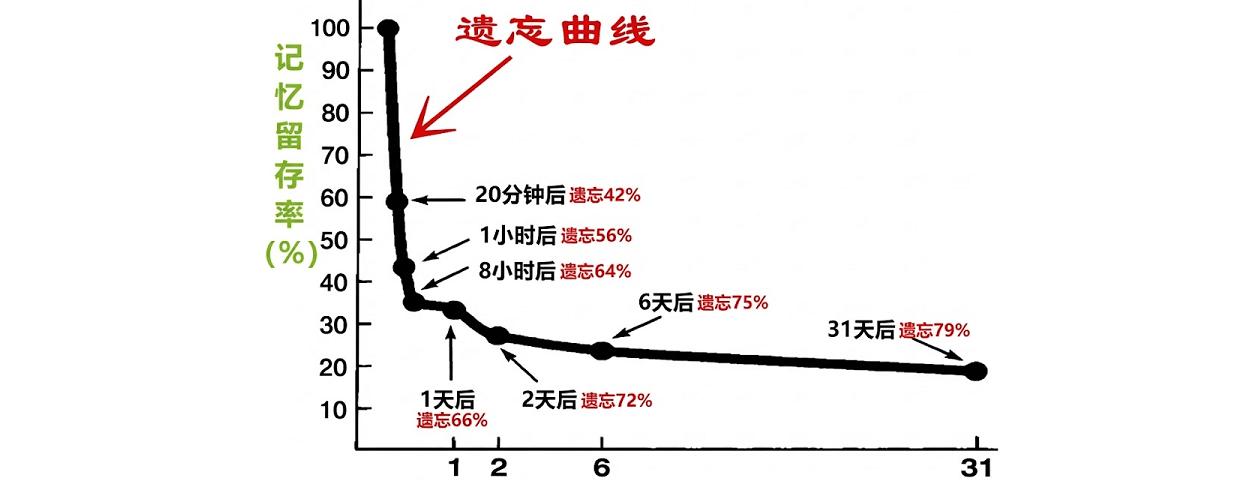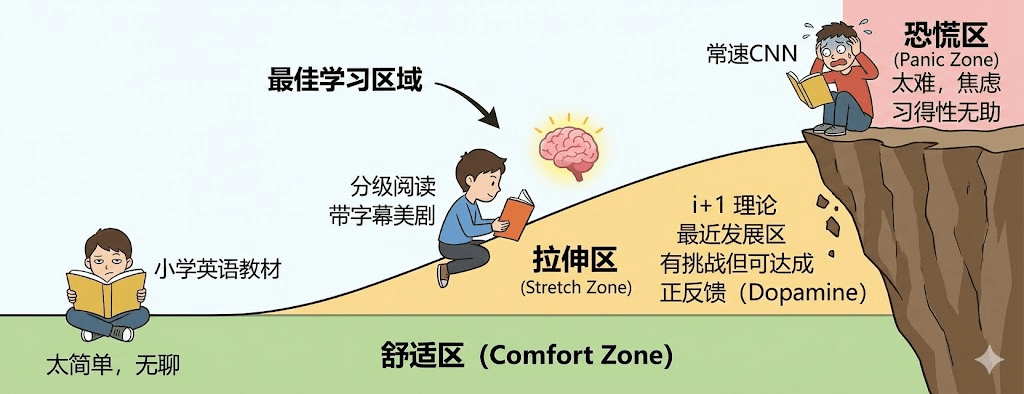
为什么你不需要最贵的模型?一个实用主义者的'AI 降维打击'
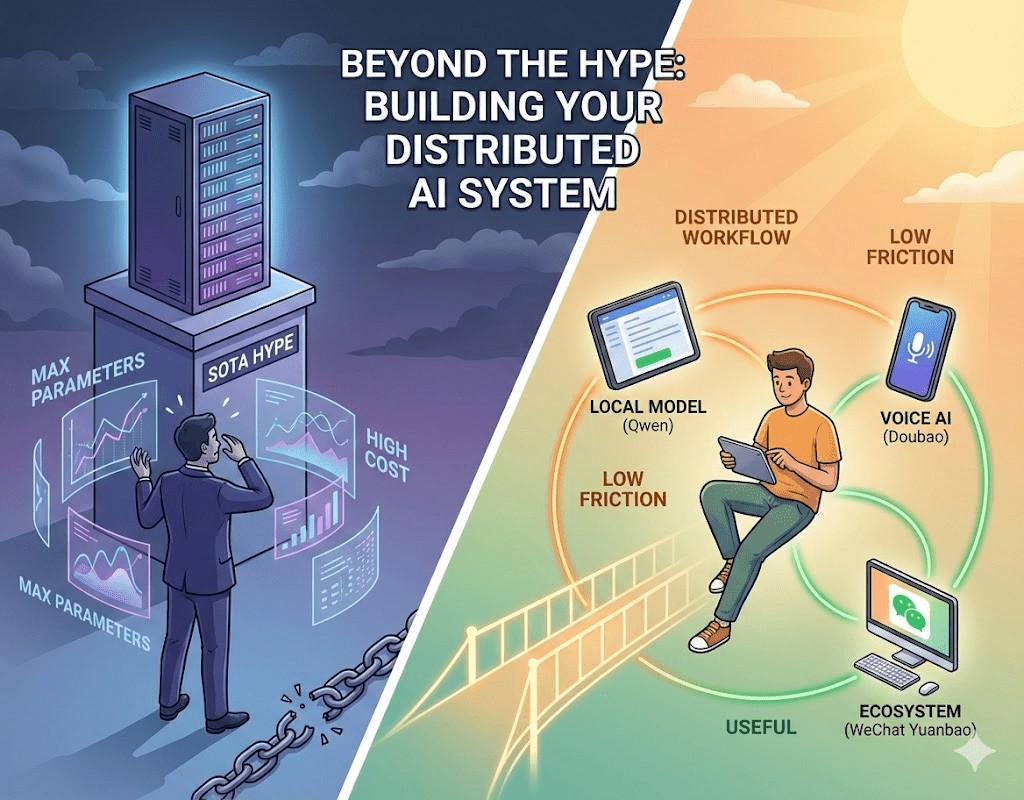
一、 引言:被“神话”的 SOTA 与被忽视的“合用” 在当下的自媒体环境中,关于人工智能的讨论正陷入一种近乎狂热的“参数崇拜”。每当 OpenAI、Google 或 Anthropic 发布新模型,社交媒体上便充斥着各种跑分图表和“最强模型”的惊叹号。似乎如果你不在使用最新的 SOTA(State-of-the-Art,顶尖水平)模型,你的工作效率就低人一等,你就在被时代抛弃。 这种现象本质上是一种 “信息焦虑的变体” 。人们试图通过持有最先进的工具,来对冲对未来不确定性的恐惧。然而,作为一个深度使用 AI 的实用主义者,我观察到了一个被多数人忽视的真相:AI 的本质是杠杆,而杠杆是否好用,不在于它是否是最新材料制成的,而在于它是否匹配你的支点和力度。 我个人认为,盲目追求最高参数是没有必要的。真正高效的 AI 应用标准应该是:合用、方便,且能真实提升信息获取质量。 二、 逻辑重构:为什么“合用”比“最强”更具优势? 要建立高效的 AI 工作流,首先要破除“大模型全能”的迷信,从三个底层逻辑重新审视工具的价值。 1. 认知激活能:降低“开启任务”的门槛 任何工具的使用都有“启动成本”。如果你为了翻译一段话,需要翻墙、登录网页、输入复杂的提示词,这种高昂的“认知激活能”会让你在潜意识里产生抗拒。相反,像“豆包“或微信里的“元宝”,由于它们嵌入了你原有的生活生态,几乎实现了“零成本开启”。最好的工具是让你感觉不到它的存在,而不是让你去“适配”它。 2. 边际效用递减:速度本身就是质量 在 80% 的日常任务中(如总结摘要、简单翻译),顶级模型与中型模型的表现差异极小。为了追求那 1% 的逻辑严密性,而忍受更慢的响应速度和昂贵的订阅费,在经济上是不划算的。对于信息流处理而言,“低延迟”带来的思考连续性(心流),其价值远超“超前参数”带来的细微准确度。 3. 局部优势:生态集成胜过模型性能 一个在微信生态内运行的模型(如元宝),天然拥有对公众号文章、社交语境的理解优势;一个国产模型(如蚂蚁灵光),在处理中文技术语境和本地政策细节时,往往比远在海外的旗舰模型更“懂行”。这种 “原生感”和数据连通性 ,是通用大模型无法通过增加参数来弥补的。 三、 深度实践:如何通过“分布式 AI”重塑信息获取流程 我不再迷信某个“超级模型”,而是构建了一个 “分布式 AI 矩阵” 。它们各司其职,像一群性格迥异的助手,层层递进地优化我的信息过滤系统。 1. 降维打击:用中型模型处理“信息粗加工” 在面对日常任务或文字解读时,我通常选择 Gemma3 27B 或 千问 (Qwen) 30B 级别的模型。 为什么够用? 这个规模的模型具备极佳的语感,同时占用显存不超过 20GB。这意味着在一块不到 2000 元的显卡上,就能实现 100+ token/s 的惊人推理速度。 实际体验: 它们就像是信息流中的“轻骑兵”,能迅速把大段的外语或繁冗的叙述转化为可读的中文,完成了第一层的“杂质过滤”。 上图是我部署的代码在Qwen3-30B模型上日常消耗token数量。主要用途是文章总结,双语翻译等。如果使用SOTA模型,在速度和费用上都是沉重的负担。 ...