逻辑的归AI,视觉的归人类:从 WebMCP 看 AI 开启“去熵化”软件重构纪元
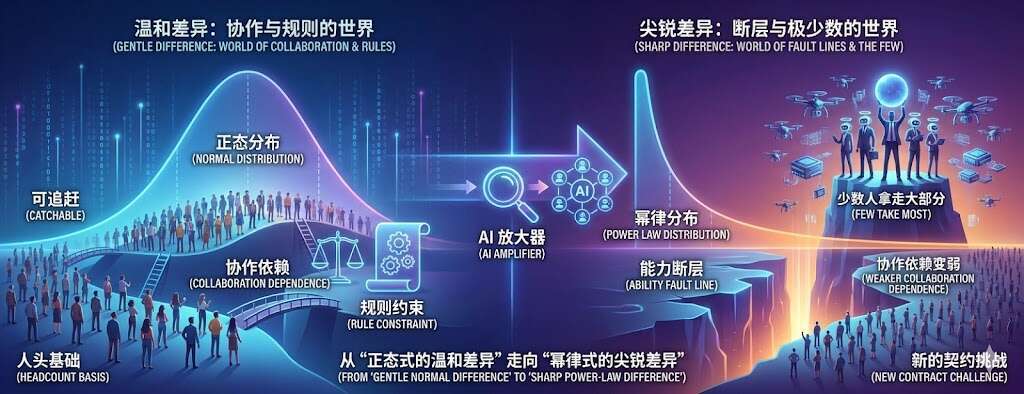
2026 年除夕之前,大家还在春运的旅途中匆匆忙忙,Chrome 团队抛出了一个会让很多开发者重新思考“Web 该怎么做”的东西:WebMCP(Web 模型上下文协议) (Web Machine Learning)。 在普通人眼里,这可能只是浏览器版本号跳了一格;但在开发者和 AI 玩家眼里,这更像是在告诉所有人:AI Agent 通过“看网页、点按钮”来完成任务的时代,会开始被改写。 虽然WebMCP 目前更像“早期规范与试验 API 的集合”,离“所有网站默认支持”的状态还很远。但它指向软件开发新范式:让网站用结构化方式,把自己的能力交给 Agent,而不是让 Agent 在像素和 DOM 里猜。市场对 AI 改造软件分发与入口的预期正在升温,相关公司股价波动也在放大这种情绪。 不过这里也需要讲清楚:WebMCP 更像一个方向与实验接口集合,API 形态未来仍可能变化;它能否真正走出实验阶段,取决于浏览器权限模型是否成熟、站点采用率是否提升、以及是否能形成跨浏览器的共识与兼容。 一、错位的遗产:HCI 是一道为人类视觉修筑的“围墙” 在讨论 AI 为什么上网如此笨拙之前,我们必须先审视过去 40 年软件工业的基石——HCI(Human-Computer Interaction,人机交互)。 传统的 HCI 核心原则是“以人为本”。因为人类的生物局限性,我们无法直接读取二进制代码,所以软件工程师们不得不耗费巨大的精力,为逻辑内核穿上一层又一层厚重的“视觉马甲”: 层级导航:因为人类一次只能关注极少量的信息,所以我们需要下拉菜单、侧边栏和多级目录。 拟物化与视觉反馈:因为我们需要确定感,所以按钮要做成圆角的,点击时要有阴影,下单后要跳出一个绿色的钩。 像素带宽:所有的排版、插图和 CSS 动画,本质上都是为了迁就人类有限的视觉带宽,将逻辑信号“翻译”成情绪与认知更容易接收的形式。 问题的本质在于:这一切精美的设计,对 AI 而言全部是“噪点”。 现有的互联网软件体系,从来就不是为 AI 准备的。当一个以纯逻辑运行的 Agent 踏入这个世界时,它会发现这里到处都是为人类理解与操作而设计的“扶手”。 于是,荒谬的一幕发生了:AI 为了帮你在网上订一张机票,不得不变成一个笨拙的 “潜伏者”。它必须强行压抑自己的逻辑本能,去模拟人类的低效行为:它要先给网页截个屏,再像台老式扫描仪一样分析 DOM 结构,死盯着那个 HTML 里的按钮坐标,最后小心翼翼地模拟鼠标点下去。 这就好比让一个能瞬间移动的超能力者,被迫穿上臃肿的潜水服,在充满淤泥(冗余 UI)的海底,一步一步艰难挪动。 它在“演戏”:AI 本质是逻辑,却被逼着去理解人类的视觉习惯和繁琐路径。 它在缴纳“计算税”:为了看清一个网页,它得消耗大量的视觉 Token,每一帧像素识别都在燃烧真金白银。 它极度脆弱:这种“潜伏”是寄生性的。前端程序员只要随手改一个 CSS 类名,原本聪明的 Agent 就可能瞬间变成“盲人”。 ...