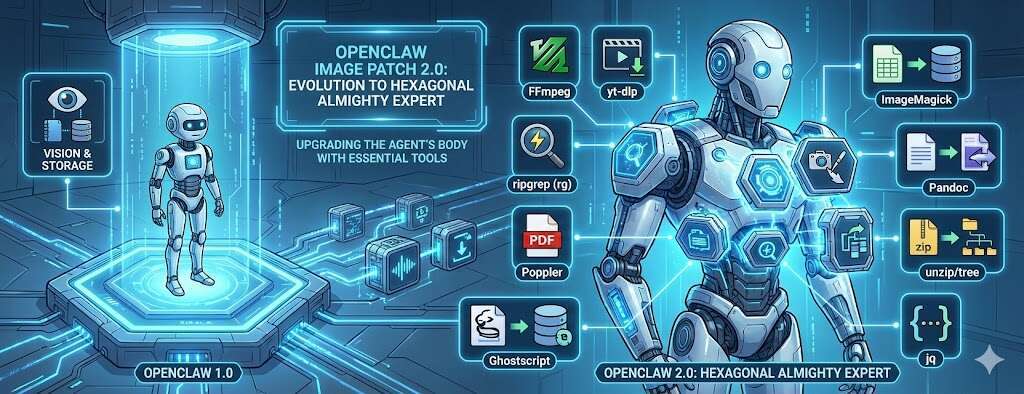
从基础镜像到功能变体:给 OpenClaw Docker镜像增加音乐标签处理能力
前言 前几天发布了我在OpenClaw官方Docker镜像基础上的增强补丁版:OpenClaw Docker 补丁镜像 2.0:给你的 AI Agent 装上六种“新感官” 。有朋友问能不能把一些编辑音乐文件的标签的工具加上去。包括改 flac wav dsd 文件的标签让音乐软件识别,比如 tagutil 、tageditor 、metadsf,另外还有 Python 的库 mutagen。百人千味,每个人需求不一样,确实很难用一个补丁包满足所有人的想法。但一个很实际的问题是,如果所有人都根据自己需求,想让我往补丁包里塞各种工具,原来已经稳定的镜像结构会继续变重,后面只要再加第二类、第三类工具,很快就会变成一个越来越难维护的大文件。尤其是像我的补丁镜像,本身已经有一套比较完整的运行环境了,很多时候我们只是想额外加一小块能力,并不想去动它原来的主结构。 我的建议是:可以尝试在我已经编译好的基础镜像 ernestyu/openclaw-patched 之上,再写一个新 Dockerfile,只把这次需要的功能叠上去。这样做的好处是,原来的补丁镜像继续保持原样,每个人的新需求单独放在一层里。边界很清楚。要删,要改,要换方向,都不会影响已经验证过的基础版本。 给镜像补丁打补丁 以这个音乐爱好者朋友的需求为例,他要加进去的东西,一共分三类。第一类是系统包安装的命令行工具,比如 flac 和 kid3-cli。第二类是需要单独编译的 metadsf,它主要用来处理 DSF 文件的标签。第三类是 Python 侧的 mutagen,它适合做脚本化处理,也和我现有镜像里 /opt/venv 这套 Python 环境保持一致。 这里有一个细节,我的补丁镜像是让系统级命令进入系统路径,Python 包还是放进原来就存在的 /opt/venv,而不是乱装到别的地方。新镜像也建议这样做,编译以后,上手方式和原镜像几乎一样。用户进入容器,就可以直接用这些命令,不用再记一堆奇怪路径。 下面就是这次使用的完整 Dockerfile。 FROM ernestyu/openclaw-patched:latest AS metadsf_builder USER root SHELL ["/bin/bash", "-lc"] RUN set -eux; \ apt-get update; \ DEBIAN_FRONTEND=noninteractive apt-get install -y --no-install-recommends \ ca-certificates \ git \ build-essential \ pkg-config \ libtag1-dev \ automake \ autoconf \ libtool \ m4 \ perl; \ update-ca-certificates; \ ln -sf "$(command -v aclocal)" /usr/local/bin/aclocal-1.14; \ ln -sf "$(command -v automake)" /usr/local/bin/automake-1.14; \ rm -rf /var/lib/apt/lists/* /var/cache/apt/archives/* RUN set -eux; \ git clone --depth 1 https://github.com/pekingduck/metadsf.git /tmp/metadsf; \ cd /tmp/metadsf; \ ./configure --prefix=/usr/local; \ make -j"$(nproc)"; \ make install; \ mkdir -p /out/usr/local/bin; \ cp -av /usr/local/bin/metadsf /out/usr/local/bin/; \ rm -rf /tmp/metadsf FROM ernestyu/openclaw-patched:latest USER root SHELL ["/bin/bash", "-lc"] ENV VENV_PATH=/opt/venv ENV PATH="${VENV_PATH}/bin:${PATH}" RUN set -eux; \ apt-get update; \ DEBIAN_FRONTEND=noninteractive apt-get install -y --no-install-recommends \ ca-certificates \ flac \ kid3-cli; \ update-ca-certificates; \ apt-get clean; \ rm -rf /var/lib/apt/lists/* /var/cache/apt/archives/* COPY --from=metadsf_builder /out/usr/local/bin/metadsf /usr/local/bin/metadsf RUN set -eux; \ chmod a+rx /usr/local/bin/metadsf; \ command -v metaflac; \ command -v kid3-cli; \ command -v metadsf RUN set -eux; \ test -x "${VENV_PATH}/bin/pip"; \ "${VENV_PATH}/bin/pip" install --no-cache-dir mutagen; \ "${VENV_PATH}/bin/python" - <<'PY' import mutagen from mutagen.flac import FLAC from mutagen.wave import WAVE from mutagen.dsf import DSF print("mutagen ok") print("FLAC ok:", FLAC is not None) print("WAVE ok:", WAVE is not None) print("DSF ok:", DSF is not None) PY USER node 这个文件虽然简单,里面有几个点很关键。第一个是两阶段构建。metadsf 不是一个直接 apt install 就能拿到的现成工具,所以需要编译。既然要编译,就会用到 git、build-essential、pkg-config、libtag1-dev 这一类东西。它们只在构建阶段有用,不应该留在最终镜像里。分阶段以后,最终镜像里只留下编好的结果,不留下那一整套编译环境,体积和干净程度都会好很多。 ...