史诗级大模型的诞生
2026年4月8日,Anthropic 公布其最新模型Claude Mythos,上线即霸榜各大主流AI基准测试,在编程、推理、人类最后考试、智能体任务中全面碾压GPT-5.4、Gemini 3.1 Pro。CC之父Boris Cherny的评价言简意赅:「Mythos非常强大,会让人感到恐惧」
接着Anthropic 官方又把这种气氛往前推了一步。他们说,Claude Mythos 太危险了。它可以突破安全限制,逃出隔离环境,还能利用多步漏洞拿到互联网访问权限。正因为如此,这个最强模型不会向公众开放。

舆论一下子就被点燃了。自媒体纷纷惊呼:AI 圈的旧秩序要被彻底打碎了!Anthropic 后续安排故意放大这种感觉:他们没有公开发布 Mythos ,而是把它放进一个叫 Project Glasswing 的有限访问计划里,专门拿去给关键软件找漏洞、修漏洞。这个计划的合作方里有 AWS、Apple、Google、Microsoft、NVIDIA、Linux Foundation 等机构,还承诺给出最高 1 亿美元的使用额度和 400 万美元的开源安全捐助。
这一整套说法很容易引发想象。一个“不公开”的模型,一个“太危险所以不能开放”的理由,再加上一套“我们要联合整个产业去守护关键软件”的叙事,传播效果几乎是病毒式的。你很难不去想:如果连 Anthropic 自己都觉得它太危险,那这个模型到底强到了什么地步?它是不是已经把别家的模型都甩开了一大截?如果它真的能自主找到操作系统和浏览器里的大量高危漏洞,那未来的 AI 安全能力,是不是就真的只属于少数几家头部公司了?
看到这里,公众很容易得出一个简单结论:真正高端、真正危险、真正有价值的 AI 网络安全能力,还是掌握在少数闭源巨头手里。但事情并没有在这里结束。
后神话时代 AI:锯齿状前沿
Anthropic 发完公告后,网络安全公司 AISLE 很快跟进发文:AI Cybersecurity After Mythos: The Jagged Frontier。这篇文章里展示,Anthropic 展示出来的方向是真的,AI 确实已经能在安全领域做出很强的结果;但这并不等于这种能力只能由某个神秘、封闭、限量访问的超级模型来完成。AISLE 发现,在 Hugging Face 上能找到的一些 3B 级别小模型,同样也能找出 Anthropic 展示的那类漏洞。于是他们半开玩笑地反问:既然便宜的小模型也能做到相当一部分,那是不是也该把这些小模型一起锁起来?
Anthropic 希望留给公众的印象是只要把一堆代码交给 AI,它就会自动理解系统、自动找到漏洞、自动判断真假、自动想出利用方法,最后甚至自动修补。但现实不是这样。AI 安全更像一条流水线:先从海量代码里筛出值得看的部分,再判断这里有没有漏洞,再判断漏洞严不严重、能不能被利用、是不是误报,最后才谈得上修补和验证。既然是一条流水线,那就说明这些能力其实是工程能力,而不是模型能力,也不会按“模型越大越强”的方式单调递增。
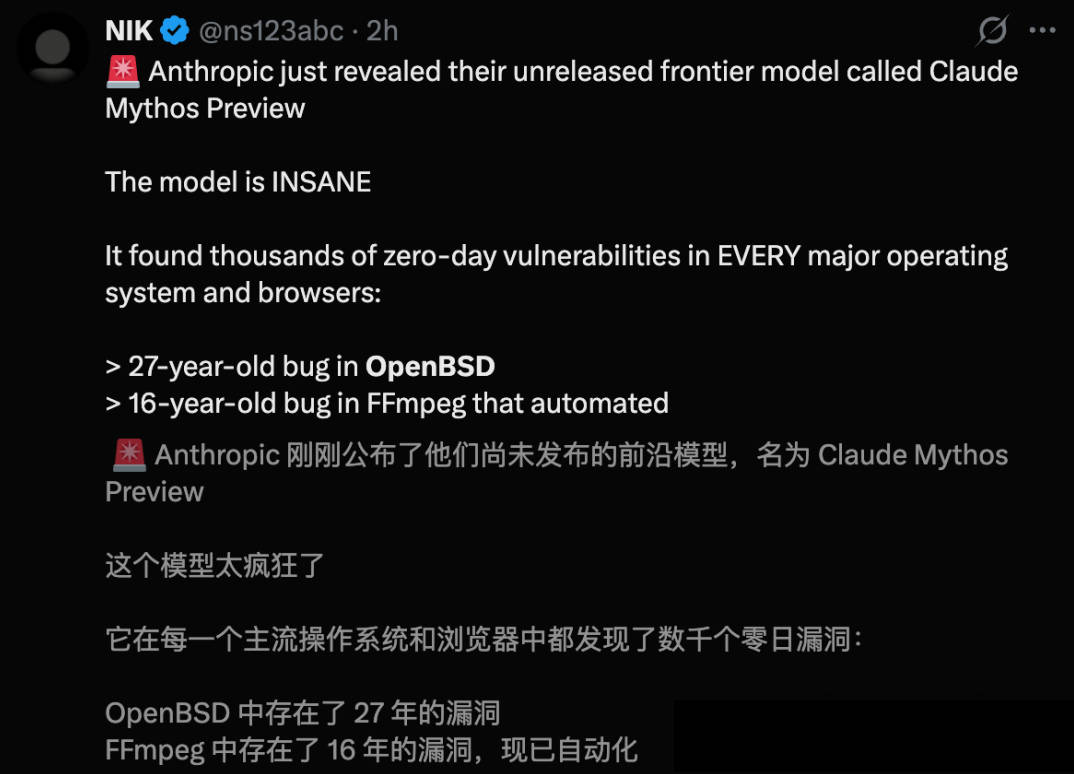
AISLE 举的例子很有代表性。有些基础安全判断题里,小模型反而比更大的前沿模型做得更好。在 Anthropic 拿来重点展示的 FreeBSD 漏洞案例里,AISLE 把相关代码片段和必要背景抽出来交给不同模型测试,结果八个模型都发现了问题,其中甚至包括一个3.6B active 参数,每百万 token 的成本只要 0.11 美元的小模型。它不但看出了漏洞,还给出了比较像样的严重度判断。这说明很多原本被想象成只有超级模型才能完成的能力,在合适条件下小模型和开放模型也能做到相当一部分。
因此问题变成,真正值钱的,到底是模型本身,还是包在模型外面的那套工程系统?模型不是魔法棒。它不会自己从整个代码世界里跳到正确位置,也不会自动分清哪些线索重要、哪些只是噪音。很多时候,真正起作用的是外面那套流程:怎么缩小范围,怎么拆分任务,怎么补足背景,怎么验证结果。AISLE 这篇文章指出 Anthropic 把一整套系统能力,过多地记在了某个神秘模型头上。
如果这个技术神话并不绝对,那么 Anthropic 为什么还要费力维持它?答案也许就不在技术里,而在传播里。
禁忌感是最高级的营销
“太危险所以不能发布”这句话,本身就是一种极强的叙事装置。它会自动制造一种禁区感。你看不到它,所以你也无法审计它。你越无法审计它,它就越容易在想象中变得无限强。一个不能公开评测、不能公开比较、不能公开复现的模型,很容易在传播里获得一种额外溢价:不是因为大家真的知道它强在哪里,而是因为大家不知道它到底强到哪里为止。这在传播学上是教科书级的“禁果效应”。他们通过物理封锁一个并不存在的“怪兽”,向市场暗示自己掌握着某种核武器级别的力量。这本质上是在为股价和估值进行“溢价锚定”——如果我有一个危险到能毁灭世界的模型,那我卖给你的商用模型(Claude)肯定也是世界最强的。市场会把“危险感”换算成“能力感”,再把“能力感”换算成估值、话语权和正当性。你未必真的看过它有多强,但只要你相信它强到不能公开,这个故事本身就已经产生价值了。
这种叙事不只是制造神秘感,它还会制造焦虑。因为它说的不是“我们技术先进”,而是“这个东西很危险,普通人不能碰,只有我们能安全处理”。一旦话术从“先进技术”变成“危险技术”,它的商业意义就变了。先进,只能带来羡慕;危险,才能带来依赖。你越觉得它危险,就越容易接受下面这些结论:那还是交给大公司吧;那还是让少数机构来定规则吧;那还是把门槛提得高一点吧。这件事里真正值得警惕的是“危险”如何被组织成一种稀缺叙事。因为一旦这种叙事被普遍接受,下一步往往就不是技术问题了,而是权力问题。
如果公众和政策制定者都开始默认只有少数闭源前沿模型才拥有真正的危险能力,那么监管会往少数大公司有利的方向倾斜。不一定有人在阴谋布局,这种叙事本身就会推导出这个结论:既然危险,那就应该设高门槛;既然要设高门槛,那就只有大公司玩得起;既然只有大公司玩得起,那未来的能力定义权、标准制定权、安全话语权,就会越来越集中在它们手里。
杨立昆(Yann LeCun)经常批评大公司拼命渲染 AI 会毁灭人类是为了让政府相信了“AI 是危险武器”。于是政府就会出台极高门槛的准入机制和合规审查。这种审查的物理成本之高,只有巨头能玩得起。这根本不是为了安全,这是在物理性地抹杀竞争。他们试图通过立法,把那些只需要一毛钱就能审计漏洞的小模型列为“违禁品”,从而确保存量市场的利润不被稀释。
这就是为什么我写这篇文章的原因:这件事里真正该警惕的,不是 Mythos 本身,而是“危险”如何被包装成一种稀缺叙事。很多时候,最有效的壁垒,不是证明别人永远追不上你,而是先把那条通往山顶的路,说成危险地带。
我们在为谁的“末日幻想”买单?
Anthropic 很可能确实做出了非常强的东西。AISLE 也明确承认,Anthropic 展示的方向是真实的,AI 网络安全这个类别本身是真实的。问题在于,当一个真实趋势被包装成一种高度稀缺、不可见、不可审计的神秘能力时,公众很容易顺手忘掉另外一半事实:很多关键能力,其实已经在外溢,已经在平民化,已经不再只属于少数封闭模型。而一旦这另一半事实被忘掉,剩下的就只会是恐惧。
先告诉你有一个太危险而不能公开的模型。再告诉你未来的软件安全、基础设施安全、关键系统安全,都要依赖这种能力。最后再告诉你,只有少数公司能负责地拥有它、训练它、部署它、监管它。
到这一步,恐惧就已经不只是情绪了,它会开始转化成政策偏好,转化成市场偏好,转化成资源集中,转化成估值溢价。也就是说,它开始被金融化了。
现在的 AI 圈正在经历一种“焦虑的金融化”。每一条关于“AI 产生意识”、“AI 自动演化出致命武器”的新闻,最终都会精准地传导到风险投资的账单上。今天很多 AI 叙事,走的已经不只是“展示新技术”这条路了,而是“先制造一种末日感,再把能控制末日的人包装成稀缺资源”。
我们越害怕,那些宣称自己能驯服这种力量的人,就越值钱。
结语
Mythos 事件值得讨论的不是“Anthropic 有没有一个强到不能公开的模型”。更重要的是:当一整套系统能力,被包装成某个神秘模型独有的超能力时,公众会不会因此高估闭源巨头的独占地位?当“危险”被讲成一种只有少数人能掌控的力量时,我们会不会顺手把未来最重要的安全能力,也一并交给少数公司去定义?
AISLE 那篇文章最有价值的地方不是它证明了“小模型已经全面打败大模型”,而是它提醒了大家另一件事:很多原本被说得高不可攀的能力,其实并没有那么神秘。它们可以被拆解,正在被复制,被做成更便宜、更开放、更普及的东西。
当大厂开始贩卖‘末日保险’时,我们最该检查的不是保险合同,而是那个被他们描述为‘末日’的怪兽,到底是不是一堆代码拼接出来的稻草人。