我们并不缺文章和笔记收藏工具。浏览器收藏夹、微信收藏、稍后读、Notion、Obsidian,这类工具已经足够多了。可笔记存得越多,你反而越容易觉得那只是文本的堆积,并没有真正沉淀成可用的信息,更不要说进一步转化成知识。明明收藏了很多东西,你却说不清自己最近到底在关注什么;你也许还记得某个模糊的主题,但真到要找的时候,又想不起具体标题和关键词,怎么都翻不出来。面对积累已久的笔记,你甚至很难回答一个简单却重要的问题:自己的时间,到底花在了哪里?
最近我为OpenClaw开发了一个知识库skill,clawsqlite-knowledge。我的本意是想让这个知识库借助向量能力,更好地解决搜索和回忆的问题。可用了一段时间以后,我慢慢发现,除了“怎样搜索得更好”,还有一件更有意思的事:能不能让知识库自己长出一点结构?
于是,我开始尝试在 1024 维 embedding 空间里做两阶段的兴趣聚类,再基于这些兴趣簇生成周期报告。这样一来,知识库就不再只是一个存放文章的地方,它还会反过来告诉你:你最近到底在看什么,你的关注正在朝哪些方向升温,哪些兴趣点又在慢慢冷却。
clawsqlite-knowledge 是什么
如果没有用过 clawsqlite-knowledge,可以先把它理解成一个围绕 SQLite 搭起来的本地知识库 CLI。推荐你先读一下这篇介绍:把收藏夹从“数字坟墓”变成可搜索知识库:我的 clawsqlite-knowledge 实战。
它主要处理的场景是这样的:你看到一篇微信公众号文章、一条长微博、一串 X 上的推文,或者一个 GitHub 项目,觉得有趣或者有用,就可以把网络链接推给 OpenClaw,让它录入 clawsqlite 数据库。clawsqlite-knowledge 这个 skill 会启动网页抓取脚本抓取全文,清洗成 Markdown。接着,文章标题、摘要、标签、路径等结构化信息会被写入数据库。
在这套流程里,文章前 1200 字加最后一段会被用来生成长摘要,再从长摘要中进一步提取标签。长摘要和标签一方面会被用来建立关键词索引,另一方面也会被向量化,建立向量索引。这样做的结果很实用:Markdown 文件本身可以直接打开阅读;SQLite 则负责把这些分散的文件组织成一套可检索、可统计、可关联的知识仓库。clawsqlite-knowledge 做的,就是把文件系统、数据库、全文索引和向量索引拼成一套完整的本地知识基础设施。
为什么这里要同时建立两套索引,也就是关键词索引和向量索引?因为关键词搜索本质上需要一对一匹配:你得先知道自己要搜什么词,系统才有机会把它找出来。大多数笔记软件的搜索能力,基本也就停在这里。可人的记忆和兴趣,本来就不是按关键词组织的。很多时候,你记得的只是一个模糊印象。比如,“有一篇讲大模型工具链数据流的问题写得很好”。这种记忆并不对应一组准确的关键词,你拿它去做普通搜索,往往徒劳。还有些时候,你想找的并不是某一篇具体文章,而是某个主题相关的一批内容。可这些内容虽然在语义上很接近,标题、标签和摘要里的字面表达却可能完全不同,这时候关键词搜索也很难发挥作用。这就是我给 clawsqlite-knowledge加上关键词和向量混合检索的原因。
向量索引的本质,是把语义相近的文本映射到向量空间里彼此靠近的位置。这样一来,即使它们在字面表达上很不一样,系统仍然有机会把它们联系起来。包括不同语言中含义相近的词,也可能在空间中相互接近。因此,向量检索天然适合同义表达、多语种内容以及模糊主题的混合搜索。实际打分时,向量相似度、全文匹配、标签语义、标签词面、优先级和时效性会一起进入综合评分。这样一来,即使你的表达不够精确,系统也更有可能把真正相关的内容找出来。
做到这一步以后,知识库的“查找能力”已经明显上了一个台阶。但这还不是终点。
我到底在关心什么
当知识库开始稳定以后,你的关注点会慢慢发生变化。一开始,你想做的只是把重要的东西收进来,尽量让它们可搜索、可回看。可当库里的内容越来越多,另一个问题就会浮出来:这些内容之间,是否存在某种比标签更自然的结构?它们能不能自动分成若干个方向?如果可以,这些方向是不是就能反过来帮助我理解自己?比如,我收集了这么多东西,它们大致可以分成哪些兴趣方向?哪些方向是长期稳定的?哪些方向是最近突然冒出来的?哪些方向曾经很热,现在却基本不更新了?
这些问题,单靠标签很难回答。因为标签本质上还是人工命名,而人工命名往往是随意的。时间一长,标签的颗粒度、口径和边界都会混在一起。无数个夜晚,我都在为笔记到底该按目录存储,还是按内容打标签而反复折腾。可文章一多,标签几乎立刻就开始失效。
后来我开始意识到,既然向量本身就是文章在语义空间里的坐标,那么完全可以直接利用这个空间结构来做聚类。只要语义空间不是完全混乱的,主题相近的文章就应该自然靠近,进而形成一些“簇”。这些簇不一定和人工标签一一对应,但它们更接近内容本身在讲什么,也更接近你真实在关注什么。这其实是一种自动长出来的兴趣结构。你不需要再手工给文章补更多标签,知识库自己就会慢慢显出一些轮廓。
兴趣簇是怎么长出来的
我的目标,是尽量利用向量语义,获得一组相对稳定、又尽可能可解释的兴趣簇。在这套设计里,聚类直接在原始的 1024 维向量空间里完成。整个过程分两阶段。
第一阶段,会先用一个偏大的 $k$ 跑一轮 k-means。这里的 $k$ 不是越精确越好,而是故意设得偏大一些,好把原本可能混成一团的大主题先打散。跑完以后,再检查哪些簇太小。如果某个簇里只有极少数文章,小到不足以说明它是一个可靠主题,就把这些点重新分配到最近的大簇里。
第二阶段,则会基于第一阶段得到的候选簇心继续做合并。具体来说,就是检查这些簇心之间的余弦距离。如果两个兴趣簇的中心非常接近,就可以认为它们在语义上足够近,适合合并成一个更大的兴趣组。
这套两阶段方案,比较符合真实语义结构常见的样子。很多主题之间的关系并不是严格分开的,而是“接近,但又不完全相同”。如果只做一次聚类,你很难同时兼顾细粒度和整体性。先拆后并,通常更容易得到既有辨识度、又有一定隔离度的结果。
参数决定细节
聚类是一种无监督方法,本来就没有唯一正确答案。所以,参数并不是一个无关紧要的细节,它直接决定了你最后看到的到底是一张有层次的兴趣地图,还是另一团更复杂的混合物。这里有几个参数值得单独解释。
min_size 控制的是“一个簇小到什么程度,就不值得单独存在了”。如果一个簇只有极少数文章,它往往不稳定,也很可能只是初始聚类时偶然分出来的碎片,所以需要并回更大的邻近簇。原文默认值是 5。
max_clusters 控制的是第一阶段初始拆分的上限。它决定了你一开始把知识库拆得有多细。值越大,初始碎片越多;值越小,初始结果越粗。默认是 16。
CLAWSQLITE_INTEREST_MERGE_DISTANCE 则是第二阶段里最关键的阈值。它决定了簇心之间要近到什么程度,才允许合并。这个值越小,系统越保守,最后保留下来的兴趣簇越细;值越大,合并越积极,最后的簇就越粗。原文给的内部 fallback 是 0.06。
另外还有一个 CLAWSQLITE_INTEREST_MERGE_ALPHA,它会根据真实簇结构自动推一个建议阈值。这个值不一定直接拿来当最终参数,但可以帮助判断当前知识库在什么尺度下更适合合并。
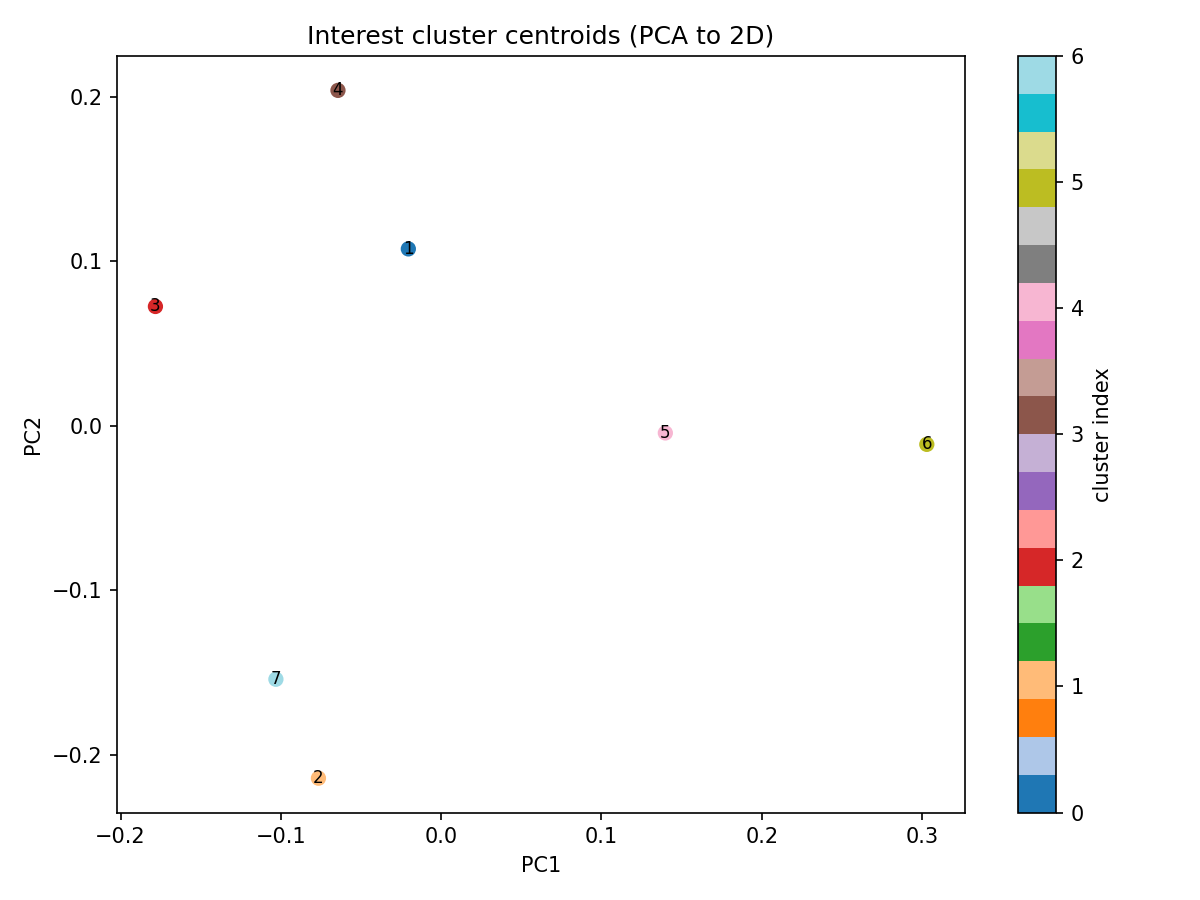
所以,clawsqlite 的兴趣簇并不是“跑一次算法就完了”。第二轮还会继续观察第一轮结果的簇内平均半径、最大半径、簇心间距离分布,以及二维投影图里这些簇到底是彼此分开,还是又重新糊成一团。参数调得好,你看到的是一张可读的兴趣地图。下图就是我测试用数据库中 150 篇文章,根据向量投影聚类得到的 7 个兴趣簇。
动态“兴趣体检”
到这一步,clawsqlite 知识库已经比传统笔记软件强很多了。因为它不只是“能搜得到”,而且开始长出“结构”。但目前为止它仍然只是一个静态快照。你能看见若干兴趣簇,却看不见这些兴趣簇随时间变化的样子。我们在意的恰恰是变化。
真正有价值的问题不只是“我有哪些兴趣”,而是“这些兴趣最近有没有在变化”。哪些方向正在升温,哪些方向已经冷了下来,哪些主题你过去连续几周都在看,哪些方向则已经被你无声地放下了。这些问题,单次聚类回答不了,就需要一份周期性报告。
clawsqlite-knowledge 增加了一个 report-interest 子命令,会生成 Markdown 报告和图表,也可以进一步输出为 HTML。
首先,周报能告诉你最基础的事实:这周一共新增了多少篇文章。这一步不能少,因为很多人对自己的阅读和收集节奏其实并没有准确感觉,总觉得“最近应该看了不少”,可一旦落到数字上,才发现也许一周只收了几篇,或者某几天完全空白。
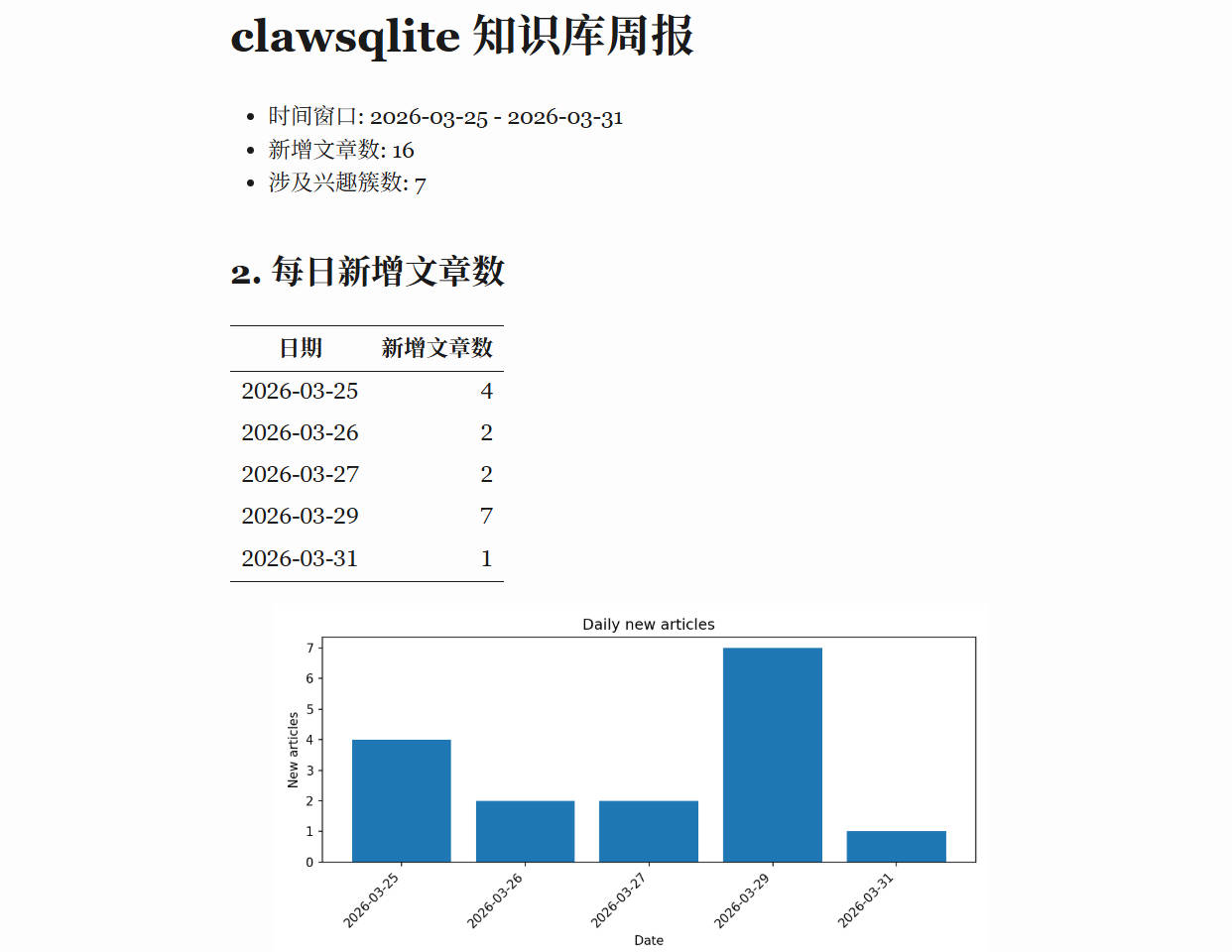
其次,报告还要回答“这些新增内容分布在什么地方”。它会设计两类分布统计:一类按天,一类按兴趣簇。前者用表格和柱状图展示每天新增多少篇,帮助你看出有没有明显的空窗日,或者某几天是否突然爆量;后者则统计每个兴趣簇里有多少篇文章、占比多少,以及簇内的 mean_radius。这些信息放在一起,很容易看出自己最近是不是一直围着同一个主题打转。
报告还不只是列出“哪个簇有几篇文章”。它会给每个簇做一个主题概括,并列出最近的代表文章。这个主题概括并不是随便从全文里抓几个词,而是优先从 tags 里找,再用轻量关键词补齐,控制在五个 token 以内

上面这张簇心 PCA 散点图也会加入到报告中。这里的 PCA 只是为了绘图,不参与真正的聚类。每个点对应一个兴趣簇,大小与簇大小相关,颜色映射簇内平均半径。你可以从图里看出哪些簇彼此靠得近,可能属于同一个大主题下的不同子簇;也能看到哪些簇相对孤立,代表一种更独立的小众兴趣。
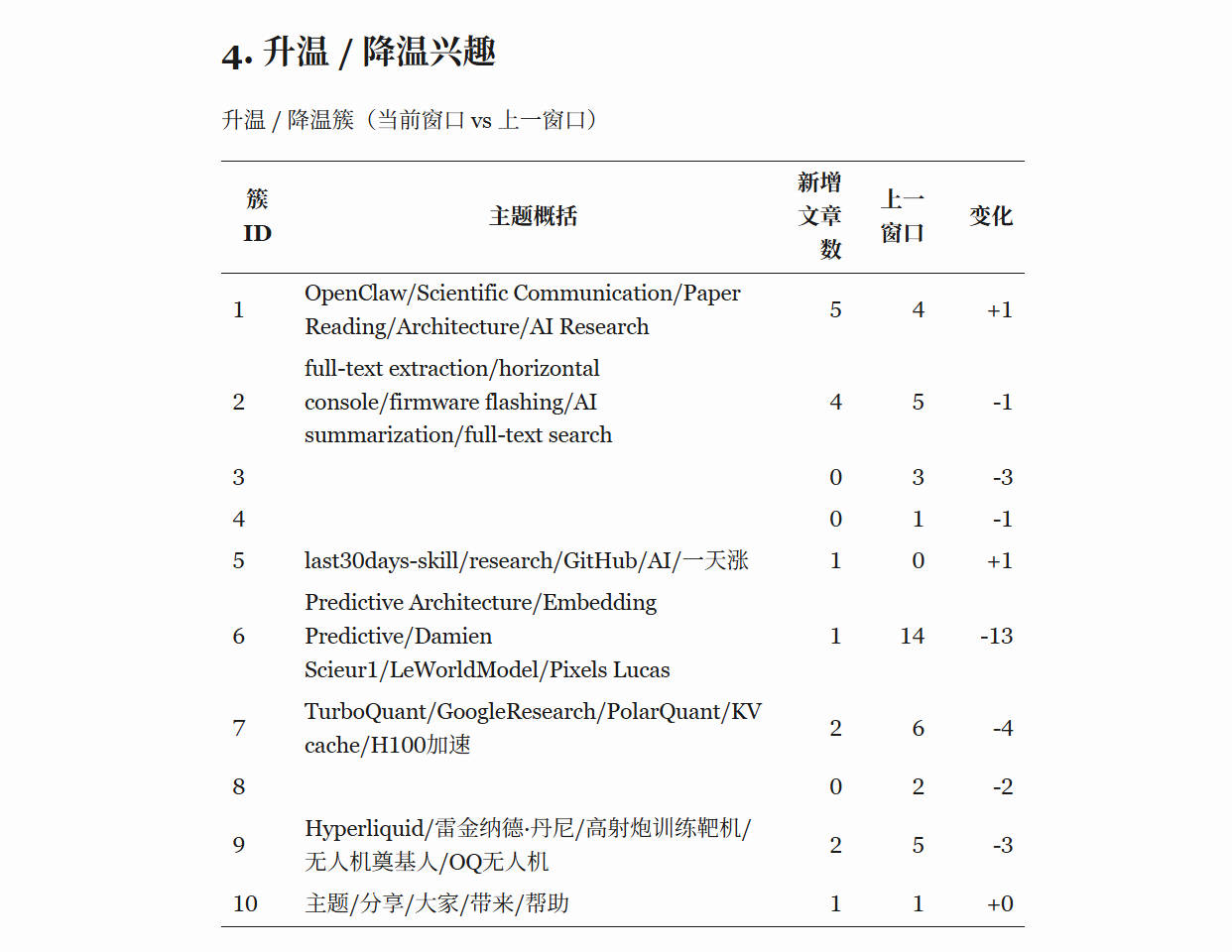
最后,也是最像“知识体检”的部分,就是升温和降温簇分析:拿当前时间窗口和前一个等长窗口做对比,统计每个簇新增文章数的差值,然后列成表。这样一来,你不只是知道“这周我看了什么”,还会知道“我的注意力正在往哪里移动”。有时候,一个方向不一定总量最多,但它增长最快,那它很可能就是你最近真正的新兴趣。
不只是搜索体验
从表面上看,clawsqlite + 兴趣簇 + 周报 做的事情,好像只是给本地知识库加了几层分析能力。但它带来的变化,其实不只是“体验更好”这么简单。它把知识库从一个被动仓库,慢慢变成了一个能反过来解释你的系统。
过去的收藏工具,主要解决的是“留下来”。你看到一篇文章,点一下收藏,它就在那里了。以后要是想找,去搜一搜,也许还能找出来。这种模式当然有价值,但它本质上更像仓储。你在不断增加库存,可库存本身并不会主动告诉你,你到底在积累什么。兴趣簇和趋势报告补上的,正是这一层“解释能力”。
它至少带来了四个变化。第一,是从“能搜到”走向“看得见结构”。向量检索解决的是模糊查找,兴趣簇则让这些内容在空间里长成一些可以辨认的“岛屿”。第二,是从“有堆积”走向“有节奏”。每周看一次报告,你至少会被迫面对自己这周到底有没有输入,是不是一直围着同一个主题转。第三,是从“我在记什么”走向“我在关心什么”。这一点尤其重要,因为它把知识管理从记账式累积,推进到了长期兴趣结构的观察。第四,是它为后续自动化提供了支点,比如做基于兴趣簇的多样性推荐、冷启动推荐或者长期提醒。
真正有意思的知识库,不是一个越来越大的抽屉,而是一个能在长期使用中,逐渐暴露出你自己思维轨迹的系统。当它开始能回答“你最近在看什么”“你对什么越来越投入”“你多久没碰过某个重要方向”这种问题时,它的价值就已经超过了普通收藏工具。
对我个人来说,现在这一步其实已经很有用了。它让我不再只是机械地把文章扔进收藏夹,而是开始定期回头看,自己的知识库到底长成了什么样。收藏本身从来不是目的,真正有价值的是,你能不能从这些被留下来的内容里,看见自己的兴趣结构,看见自己的注意力轨迹,看见自己在慢慢变成什么样的人。
如果一个知识库能做到这一点,那它就不再只是一个存东西的地方,而开始变成一种洞察工具。从这个角度说,我们缺的确实不是更多收藏夹。我们真正缺的,是一张能让知识自己长出结构的地图。
如果你对clawsqlite-knowledge有兴趣,可以访问ClawHub:https://clawhub.ai/ernestyu/clawsqlite-knowledge。
或者告诉你的OpenClaw安装命令:
openclaw skills install clawsqlite-knowledge
如果你已经安装过clawsqlite-knowledge则需要升级到最新版本 v0.1.13。还有clawsqlite>=0.1.8。
openclaw skills update clawsqlite-knowledge
让你的龙虾读一读README.md,它会搞定需要的一切 步骤。