前言:
OpenClaw 最近很火,但很多人部署它时只关注一件事:能不能跑起来。
对于一个可以自动调用工具的 AI Agent 来说,真正重要的其实是 权限边界和系统能力。
这篇文章介绍我做的 OpenClaw Docker 补丁镜像 2.0 —— 让 Agent 在安全容器中,一启动就拥有完整工具链。
OpenClaw 越火,风险越大
最近,一个名为 OpenClaw Exposure Watchboard 的安全观察页面持续扫描互联网,已经统计到接近 28 万个公开可达的活跃 OpenClaw 实例。这个数字一方面说明 OpenClaw 确实很火,部署量正在快速上升;但另一方面也说明,很多人只关注“能不能在我的电脑上跑龙虾”,却没有认真处理认证、访问控制和公网暴露面这些更基础的问题。对一个具备工具调用和自动执行能力的 Agent 来说,能跑起来只是第一步,更重要的问题是:这个 Agent 能接触什么文件、能执行哪些命令、能访问哪些网络资源。如果这些边界没有控制好,那么一个看似方便的自动化助手,很可能反而变成系统的安全隐患。因此,在我自己的部署实践中,我一直更倾向于优先使用 Docker 来运行 OpenClaw,而不是直接在主机系统里进行原生安装。
优先用 Docker 部署
Docker 并不天然等于安全,但它提供了一种非常重要的能力:可以明确划定运行边界。这对一个能够自动调用工具的 Agent 来说尤其关键。在实际使用中,我选择 Docker 部署 OpenClaw,主要有三个原因。
第一,权限边界更清楚。
当 OpenClaw 运行在容器中时,它能访问的文件、目录和系统工具都可以被严格限定。换句话说,你可以先划定一个安全范围,然后再逐步增加它的能力,而不是让它直接运行在整个主机环境里。
第二,资源利用率更高。
对很多家庭服务器、NAS、小型 Linux 主机,甚至 Mac mini 来说,让 OpenClaw 独占一台机器并不现实。容器化之后,可以在同一台机器上运行多个实例,不同用途的 Agent 之间也可以互相隔离。
第三,上下文更容易隔离。
在实际使用中,一个 OpenClaw 实例如果长期同时承担多种任务,很容易出现提示词风格、工具调用习惯以及工作目录互相干扰的问题。相比之下,我更倾向于在同一台机器上部署多个 Docker 化的 OpenClaw,让每个实例专注一种任务类型。
Docker 方案现实问题
Docker 带来了清晰的边界,但同时也带来了另一个现实问题:官方镜像通常会非常“干净”。这种设计对于维护者来说是合理的。镜像越精简,维护成本越低,也更容易保证稳定性。但对普通用户来说,这意味着 OpenClaw 虽然可以顺利启动,却未必具备足够的工具能力。
很多人在实际使用中都会遇到类似情况:
我想让它下载一段 YouTube 的音频和字幕,它却告诉我没有下载工具。我想让它读取一份几百页的 PDF 技术白皮书,它却无法解析。我想让它分析一份 Excel 账单,它却不知道该怎么处理表格。
有人可能会说:既然缺工具,那就在容器里手动安装就好了。从技术上讲,这当然是可行的。你可以进入容器,然后使用 apt 或 pip 安装需要的软件。但这种做法有两个明显的问题。
第一,它不规范。
每台机器、每个用户安装的环境可能都不一样,最终很难保证行为一致。
第二,也是更关键的一点:它不持久。
Docker 容器一旦被重建、升级或迁移,之前在容器内部临时安装的工具往往都会消失。到那时,你就需要重新安装一遍所有依赖。
如果只是偶尔测试,这种方式尚且可以接受。但如果你希望长期稳定使用 OpenClaw,这种反复补环境的方式很快就会变成一种维护负担。因此,更合理的办法是:直接制作一个预先打好补丁的镜像,把真正高频、真正有价值的工具一次性整理进去。
OpenClaw 2.0 补丁镜像
基于上面的考虑,我在官方镜像的基础上制作了一个补丁版本:
ernestyu/openclaw-patched
Docker Hub: https://hub.docker.com/r/ernestyu/openclaw-patched
这个镜像的目标并不是把系统变成一个“工具大杂烩”,而是补齐那些最常见、最实用、同时又不会明显增加复杂度的能力。
这样做有几个明显好处:首先,环境是稳定的。每次启动容器时,OpenClaw 都能获得完全相同的工具环境。其次,能力是持久的。容器重启、升级甚至迁移到新机器时,这些能力依然存在。最后,维护成本更低。用户不需要每次启动后再手动补环境。这也是我把这个版本称为 OpenClaw 镜像补丁 2.0 的原因。
升级原则:如非必要,勿增实体
在这次补丁的筛选过程中,我始终坚持一个非常简单的原则:如非必要,勿增实体。
可以装进 Docker 镜像的工具其实非常多,但如果只是盲目堆叠软件,很快就会出现几个问题:镜像体积迅速膨胀;系统复杂度明显上升;潜在依赖冲突增加。因此,这个补丁镜像只选择了一些非常轻量、非常稳定,同时又能明显扩展 Agent 能力的基础工具。例如:浏览器自动化、文档解析、媒体处理、数据分析和 高性能搜索工具。这些工具本身都很成熟,但一旦组合在一起,就能让 OpenClaw 的能力产生明显变化。
这篇文章就是针对这个镜像写的一篇详细指南。它合适绝大部分非主机安装OpenClaw的人。不管是NAS,Linux,还是Mac Mini,甚至是Windows(安装Docker Desktop)。但凡支持Docker,打补丁原理和安装步骤都相似。
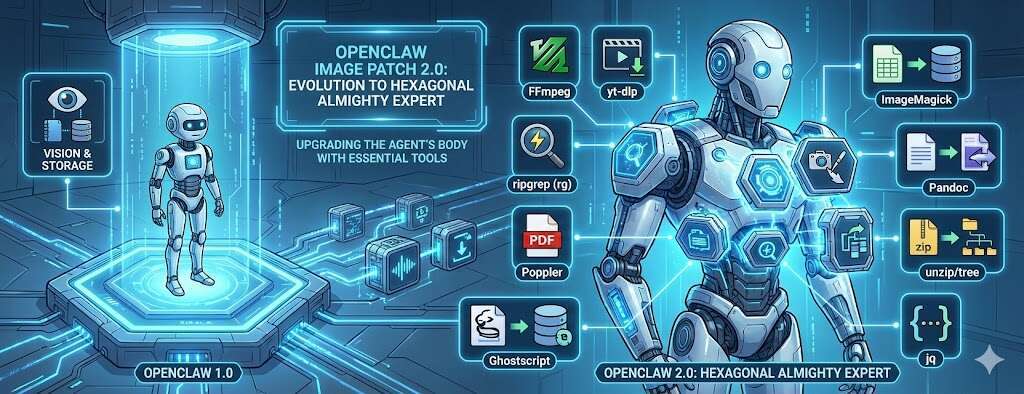
OpenClaw现在多了六种“新感官”
补丁完成之后,OpenClaw在官方镜像基础上,获得了几类新的能力。
首先是网页与浏览器能力。通过 Playwright Chromium,OpenClaw 可以真正渲染网页、执行 JavaScript,并抓取那些普通 HTTP 请求无法获取的内容。
其次是媒体处理能力。通过 ffmpeg 和 yt-dlp,OpenClaw 可以下载并处理音频和视频文件,例如提取音轨、转换格式或进行简单剪辑。
第三是文档处理能力。借助 pandoc、poppler-utils 等工具,OpenClaw 可以解析 PDF 文档,并在多种文档格式之间进行转换。
第四是数据分析能力。通过 Python 虚拟环境中的 numpy、pandas、scikit-learn 等库,OpenClaw 可以进行基础的数据处理与分析。
第五是系统级搜索能力。利用 ripgrep、fd、fzf 等高性能工具,OpenClaw 可以快速搜索文件与文本内容。
最后是本地向量检索能力。OpenClaw到现在为止的版本,其搜索能力都只支持英语这一类单词用空格分隔的语种。中日韩等文字没有自带分词插件,无法在Memory Search等功能中使用关键词匹配。这个补丁镜像通过在 Gateway 启动时加载 sqlite-vec 和 libsimple.so 扩展,使OpenClaw 可以在 SQLite 数据库中直接进行向量搜索,从而实现轻量级的本地语义检索。它没有直接解决系统级的Memory Search无法分词的问题,但现在你可以在SQLite中实现主动对中文分词,创建索引,提高中文的关键字匹配命中率。
这些能力叠加在一起之后,OpenClaw 就不再只是一个聊天助手,而更像是一个完整的自动化工作环境。
如何用 docker compose 运行
假设你现在有一个 Linux 主机环境(NAS、家庭服务器或 VPS 都可以),先在宿主机上创建一个目录,用来存放 OpenClaw 的配置和数据:
mkdir -p openclaw/data
cd openclaw
sudo chown -R 1000:1000 data
其中:
openclaw目录用于存放docker-compose.yml和.envdata目录用于持久化 OpenClaw 的工作目录
接下来在 openclaw 目录中创建 docker-compose.yml。
services:
openclaw:
image: ernestyu/openclaw-patched:latest
container_name: openclaw
restart: unless-stopped
env_file: .env
volumes:
- ./data:/home/node/.openclaw
接着启动容器:
# 停旧容器并移除(如果有的话,没有可以略过这一步)
docker compose down
# 启动新容器
docker compose up -d --force-recreate
# 看启动日志
docker compose logs -f --tail=200
做一次自检
镜像升级完成后,建议至少进行一次基础自检,确认关键工具已经正确安装。
例如,可以简单检查几个核心工具:
fd --version
magick -version
yt-dlp --version
sqlite3 --version
如果这些命令都能正常输出版本信息,就说明主要工具已经安装成功。
此外,也可以运行一次简单的 Playwright 测试,确认浏览器自动化能力正常。
让 OpenClaw 学会正确使用工具
即使系统中已经安装了大量工具,如果 Agent 不知道应该在什么情况下使用哪些工具,这些能力也很难发挥作用。
因此,在 Docker 环境中,通常需要为 OpenClaw 编写一份 TOOLS.md 文件,用来明确规定工具选择策略。例如:
- 网页抓取优先使用 Playwright
- JSON 数据处理优先使用 jq
- 文本搜索优先使用 ripgrep
- 数据库操作优先使用 sqlite3
- Python 脚本统一使用虚拟环境
当 OpenClaw 启动时,这些规则会被加载到上下文中,从而让它在执行任务时能够更加稳定地选择合适的工具。因为篇幅原因,本文不展开完整的 TOOLS.md 示例。你可以先根据上面的原则自行编写,或者等我在下一篇文章中公布完整版本。
结语:进化,是在受控中完成的
折腾到这一步,你的 OpenClaw 已经不再是一个简单的对话窗口,它已经成为了一个全知全能的“数字分身”。
最重要的是,通过这个OpenClaw2.0版镜像补丁,你确立了 “受控进化” 的准则:任何能力的增加都经过了你的授权。这种“带枷锁的舞动”,才是极客在 AI 时代最理性的生存姿态。
附录:TOOLS.md
给一个TOOLS.md去调用这些工具。把这个内容在对话中发给OpenClaw,让它去更新它的Tools.md文件,就可以了。
# TOOLS.md - Local Notes
Skills define _how_ tools work. This file is for _your_ specifics — the stuff that's unique to your setup.
## 🛠 Optimal Tool Selection Matrix (Docker Environment)
To ensure stability and efficiency in this Docker environment, follow these tool preferences.
### 1. Web Scraping & Browser Automation
- Primary: **Playwright (Node.js, playwright-core)**.
- Reason: Docker has no desktop browser session, so the "Chrome extension relay / attach tab" workflow is unreliable by default.
- Standard script location: `/home/node/.openclaw/workspace/` (place fetch/automation scripts here).
- Rule: **Always launch the browser through Playwright**. Do NOT rely on an external GUI browser or the Chrome extension relay unless explicitly configured.
Implementation notes (current image):
- Playwright core:
- Module: `/app/node_modules/playwright-core`
- CLI: `node /app/node_modules/playwright-core/cli.js …`
- Browser binaries:
- Default cache root (aligned with upstream Dockerfile): `/home/node/.cache/ms-playwright`
- Chromium lives under a versioned directory such as:
- `/home/node/.cache/ms-playwright/chromium-1208/chrome-linux64/chrome`
- Do **not** assume `/usr/bin/chromium` or `/usr/bin/chromium-browser` exists.
- When you need JS rendering, cookies, or anti-bot handling, **Playwright is the default**. Typical pattern:
const { chromium } = require('/app/node_modules/playwright-core');
const browser = await chromium.launch({ headless: true, args: ['--no-sandbox'] });
---
### 2. Media & Document Processing
- Video/Audio: **ffmpeg** Use for compression, format conversion, trimming, extracting audio, and metadata inspection.
- Images: **ImageMagick** Prefer `magick` (provided as a compatibility alias) for complex operations; `convert` also works.
- PDF (fast extraction): **poppler-utils** Prefer `pdftotext` for fast text extraction. If text extraction fails or layout is complex, use `pdftoppm` to render pages to images.
- PDF (layout/table precision, Python): **pdfplumber** (via Python venv) Use when you need accurate table extraction or layout-aware parsing.
- Document conversion: **pandoc** Use for converting between Markdown/HTML/DOCX and other formats (PDF output is optional and not required).
- Excel/CSV: **xlsx2csv** Convert Excel files to CSV for easier downstream parsing.
---
### 3. High-Performance System Tools
- Content search: **ripgrep (`rg`)** Use for searching text content in workspace, logs, and knowledge bases.
- File name search: **fd** Debian provides `fdfind`, but `fd` is available as a compatibility alias (`/usr/local/bin/fd`). Prefer `fd` in scripts for portability.
- JSON processing: **jq** ALWAYS use `jq` for JSON slicing/filtering. Do not parse JSON with regex.
- Interactive selection: **fzf** Use with `fd` and `rg` when you need to pick from many files/paths.
---
### 4. Data Sync & Database
- Cloud/Remote sync: **rclone** Use for S3 / OneDrive / Google Drive / WebDAV sync, backups, and migrations.
- Database (transparent and auditable): **sqlite3 CLI** This is the primary database interface. Keep SQL explicit so logs are auditable.
- Vector search (SQLite extension): **sqlite-vec** OpenClaw’s built-in memory already uses sqlite-vec via the Node integration. If you create your own SQLite databases for custom search, load the same extension explicitly:
- Current extension path (from `openclaw memory status`): `/app/node_modules/.pnpm/[email protected]/node_modules/sqlite-vec-linux-x64/vec0.so`
- Typical usage pattern:
sqlite3 knowledge.db \
".load '/app/node_modules/.pnpm/[email protected]/node_modules/sqlite-vec-linux-x64/vec0.so'" \
"SELECT 1;"
- If a shorter path is added later (e.g. a symlink `/usr/local/lib/vec0.so`), update this section accordingly.
Rules:
- Prefer sqlite3 CLI over language bindings (Node/Python drivers) when you need transparency and simple deployments.
- Keep `.load` paths absolute and explicit so behavior is reproducible across restarts and rebuilds.
---
### 5. Python (Anki & Knowledge Workflows)
Python packages are installed in a dedicated venv at `/opt/venv`.
Environment (current image):
- `VENV_PATH=/opt/venv`
- `PATH` has been set so that `"$VENV_PATH/bin"` comes before system paths.
This means:
- `python` / `pip` → venv (`/opt/venv/bin/python`, `/opt/venv/bin/pip`)
- `python3` / `pip3` → system Python (`/usr/bin/python3`)
Critical rules:
- For all automation and helper scripts, **use `python` / `pip` (venv)**, not `python3` / `pip3`, unless you explicitly want system Python.
- Do NOT install extra packages with system `pip` unless there is a very specific reason.
Installed Python packages (venv):
- Anki & knowledge: `genanki`, `python-frontmatter`, `feedparser`
- Web parsing: `httpx`, `beautifulsoup4` (`bs4`), `lxml`, `pyyaml`
- Data & charts: `pandas`, `matplotlib`
- Images: `Pillow`
- TTS/audio: `edge-tts`, `pydub`
- PDF precision: `pdfplumber`
- Utilities: `qrcode`, `loguru`
Practical rules:
- If you write a Python helper script, run it with:
python /home/node/.openclaw/workspace/your_script.py ...
- If you need to install additional Python packages later, do it explicitly via:
pip install <pkg>
This uses the venv `pip` and keeps everything inside `/opt/venv`.
---
## 🔧 Fixed Environment Paths (DO NOT GUESS)
- Workspace root: `/home/node/.openclaw/workspace`
- Venv root: `/opt/venv`
- Venv Python: `/opt/venv/bin/python`
- Playwright core: `/app/node_modules/playwright-core`
- Playwright browsers root: `/home/node/.cache/ms-playwright`
- SQLite-vec (current used by memory): `/app/node_modules/.pnpm/[email protected]/node_modules/sqlite-vec-linux-x64/vec0.so`