一、 引言:被“神话”的 SOTA 与被忽视的“合用”
在当下的自媒体环境中,关于人工智能的讨论正陷入一种近乎狂热的“参数崇拜”。每当 OpenAI、Google 或 Anthropic 发布新模型,社交媒体上便充斥着各种跑分图表和“最强模型”的惊叹号。似乎如果你不在使用最新的 SOTA(State-of-the-Art,顶尖水平)模型,你的工作效率就低人一等,你就在被时代抛弃。
这种现象本质上是一种 “信息焦虑的变体” 。人们试图通过持有最先进的工具,来对冲对未来不确定性的恐惧。然而,作为一个深度使用 AI 的实用主义者,我观察到了一个被多数人忽视的真相:AI 的本质是杠杆,而杠杆是否好用,不在于它是否是最新材料制成的,而在于它是否匹配你的支点和力度。
我个人认为,盲目追求最高参数是没有必要的。真正高效的 AI 应用标准应该是:合用、方便,且能真实提升信息获取质量。
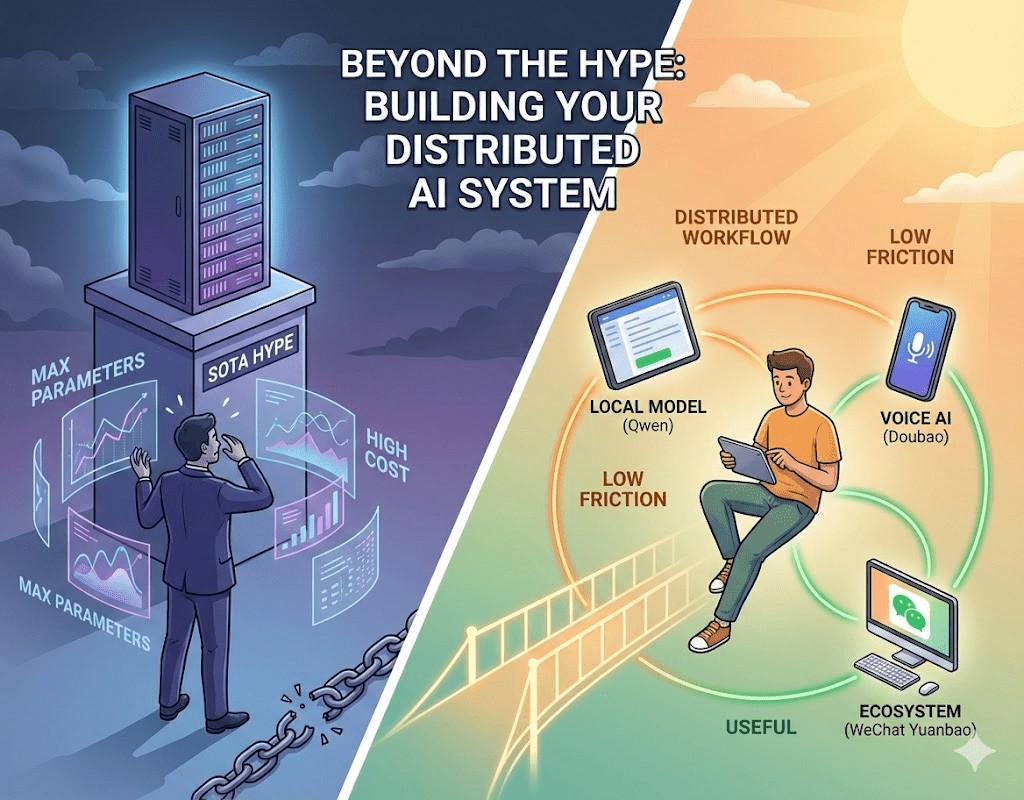
二、 逻辑重构:为什么“合用”比“最强”更具优势?
要建立高效的 AI 工作流,首先要破除“大模型全能”的迷信,从三个底层逻辑重新审视工具的价值。
1. 认知激活能:降低“开启任务”的门槛
任何工具的使用都有“启动成本”。如果你为了翻译一段话,需要翻墙、登录网页、输入复杂的提示词,这种高昂的“认知激活能”会让你在潜意识里产生抗拒。相反,像“豆包“或微信里的“元宝”,由于它们嵌入了你原有的生活生态,几乎实现了“零成本开启”。最好的工具是让你感觉不到它的存在,而不是让你去“适配”它。
2. 边际效用递减:速度本身就是质量
在 80% 的日常任务中(如总结摘要、简单翻译),顶级模型与中型模型的表现差异极小。为了追求那 1% 的逻辑严密性,而忍受更慢的响应速度和昂贵的订阅费,在经济上是不划算的。对于信息流处理而言,“低延迟”带来的思考连续性(心流),其价值远超“超前参数”带来的细微准确度。
3. 局部优势:生态集成胜过模型性能
一个在微信生态内运行的模型(如元宝),天然拥有对公众号文章、社交语境的理解优势;一个国产模型(如蚂蚁灵光),在处理中文技术语境和本地政策细节时,往往比远在海外的旗舰模型更“懂行”。这种 “原生感”和数据连通性 ,是通用大模型无法通过增加参数来弥补的。
三、 深度实践:如何通过“分布式 AI”重塑信息获取流程
我不再迷信某个“超级模型”,而是构建了一个 “分布式 AI 矩阵” 。它们各司其职,像一群性格迥异的助手,层层递进地优化我的信息过滤系统。
1. 降维打击:用中型模型处理“信息粗加工”
在面对日常任务或文字解读时,我通常选择 Gemma3 27B 或 千问 (Qwen) 30B 级别的模型。
- 为什么够用? 这个规模的模型具备极佳的语感,同时占用显存不超过 20GB。这意味着在一块不到 2000 元的显卡上,就能实现 100+ token/s 的惊人推理速度。
- 实际体验: 它们就像是信息流中的“轻骑兵”,能迅速把大段的外语或繁冗的叙述转化为可读的中文,完成了第一层的“杂质过滤”。
 上图是我部署的代码在Qwen3-30B模型上日常消耗token数量。主要用途是文章总结,双语翻译等。如果使用SOTA模型,在速度和费用上都是沉重的负担。
上图是我部署的代码在Qwen3-30B模型上日常消耗token数量。主要用途是文章总结,双语翻译等。如果使用SOTA模型,在速度和费用上都是沉重的负担。
如下图所示,即使在缺乏上下文的情况下,这种模型也能精准抓住表达重点(第一段意译中文,可以对比第二段直译中文)。这种“意译”质量,对于日常阅读早已溢出。

2. 实时伴随:用语音与AI交互打破“技术恐惧”
在上一期的Hacker Digest 018 | 零摩擦的认知陷阱,月球表面的瞬间闪光里我写过:“现代数字工具(如一键剪藏、稍后阅读)助长了“收集者谬误”,让用户产生“囤积即学习”的错觉,最终将笔记系统变成信息的坟墓。”
面对硬核文章,很多人会用“剪藏”来抚平焦虑,但没有内化的知识不会增加认知。我通过结合使用蚂蚁旗下的灵光 AI + 豆包语音输入法 来解决这个问题。
- 降低心智负担: 学习新知识本身就极度消耗精神。DeepSeek 固然强大,但解说细节过多,有时反而令人望而畏。我选择 灵光 是因为它能“恰到好处”地解释概念,用图文并茂的方式让你迅速明白核心,而不至于被细节淹没。
- 非正式输入的魅力: 为什么强调语音?键盘输入带有某种“正式感”,会打断阅读心流。而语音输入更接近“原生思考”。当你沉浸在文章中,随口问一句,理解后再继续看,整个过程极其丝滑。
比如下面的例子。你可以试一试同样问题,Deepseek是怎么回答的。

3. 深度校准:用专业工具进行“逻辑链校验”
如果你是一个微信公众号的深度使用者,可能每天都会刷到大量的新闻、视频和技术文章。这些内容未必全部是真实的,或者容易理解的。对于需要进行事实核查和深度思考的内容,我会调用微信元宝。你可以将元宝添加为对话人。然后将微信公众号或者视频号转发给它,让它进行总结,或者解惑。
- 事实核查: 微信元宝在处理细节盘问和技术事实核查时表现得非常严谨。我会要求它对文章中的数据来源进行背书,确保我不被误导。当然,灵光对于事实核查也非常有效。Deepseek在不开启联网搜索情况下只会使用训练语料。每次都要开启联网搜索也是一种负担!
- 逻辑链校验: 我经常将微信公众号的文章直接转发给“元宝”,要求它做三件事:总结梳理、事实核查、逻辑链校验。 现在的互联网充满偏见和营销话术。通过 AI 拆解文章的逻辑结构,我能清晰地看到哪些是事实,哪些是情绪,哪些是逻辑跳跃。这种“过滤器”作用,极大地提升了我摄入信息的纯度。

四、 认知升级:从“工具使用者”进化为“认知架构师”
当我们不再纠结于参数时,我们实际上完成了一次认知的跨越。
首先,我们重塑了信息过滤系统。 在信息爆炸的时代,获取信息不难,过滤信息才难。通过分布式 AI 矩阵,我们构建了一道人工无法比拟的防火墙。这不仅是效率的提升,更是对思维空间的保护。
其次,AI 赋予了我们挑战复杂性的勇气。 以往看到满篇公式的技术论文,我们可能会望而却步。但现在,有了随时待命的解释工具,我们的视野边界被极大地扩展了。AI 不仅仅是在给答案,它是在通过持续的反馈,训练我们自身的批判性思维。
最后,实用主义让我们重获技术的主动权。 追随潮流是疲惫的,但建立工作流是沉淀的。当你频繁、低成本地使用这些“合用”的工具时,你正在构建一套属于自己的知识护城河。在这个链路中,模型只是零件,而你的组合逻辑和提问深度才是真正的引擎。
五、 结语:回归工具的本质
我们正处在一个技术变革的奇点,大模型的迭代速度确实令人目眩。但请记住,我们是技术的主人,而非参数的附庸。
最成功的 AI 应用,不一定是那个在跑分榜上排名第一的模型,而是那个悄无声息地融入你的微信、你的输入法、你的阅读习惯,让你在不知不觉中读懂了以前读不懂的文章、看清了以前看不透的逻辑的那个“合用”的工具。
停止对 SOTA 的无谓追逐,开始建立你自己的“合用”工作流。 毕竟,我们需要的不是一个全知全能的神,而是一群能帮我们看清世界的影子助手。