Why You Don’t Need the Priciest Models: A Pragmatist’s Guide to ‘AI Downscaling’
Part 1: The Myth of SOTA and the Neglected “Fit-for-Purpose”
In today’s self-media landscape, discussions around artificial intelligence have spiraled into an almost fanatical “parameter worship.” Every time OpenAI, Google, or Anthropic release a new model, social media floods with benchmark charts and exclamation points about the “most powerful model.” It feels like if you’re not using the latest SOTA (State-of-the-Art) model, your productivity is subpar, and you’re being left behind by the times.
This phenomenon is essentially a “variant of information anxiety.” People try to hedge against the uncertainty of the future by owning the most advanced tools. However, as a pragmatist deeply entrenched in AI, I’ve observed a truth often overlooked: AI is fundamentally a lever, and whether that lever works well isn’t about being made of the newest material, but about whether it matches your fulcrum and force.
My take? Blindly chasing the highest parameters is pointless. The standard for truly effective AI application should be: fit-for-purpose, convenient, and demonstrably improving the quality of information acquisition.
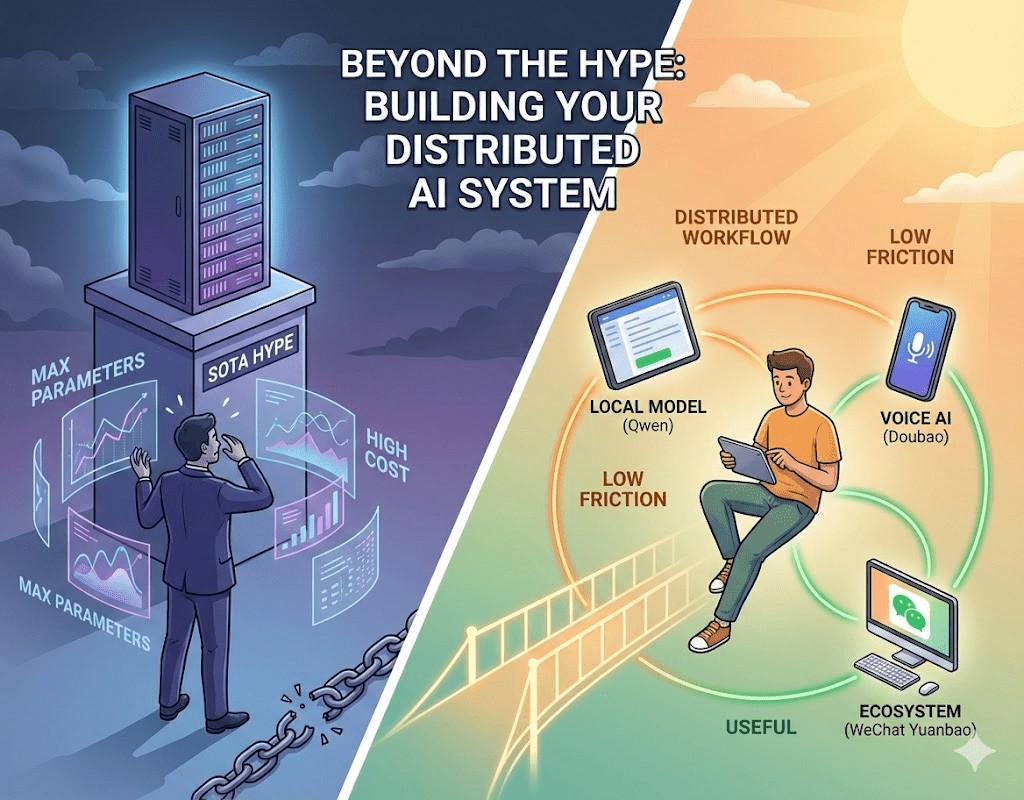
Part 2: Logical Reconstruction: Why “Fit-for-Purpose” Outperforms “Strongest”
To build an efficient AI workflow, you first need to dispel the myth of “large models as omnipotent” and re-evaluate the value of tools from three foundational logical perspectives.
1. Cognitive Activation Energy: Lowering the “Task Initiation” Bar
Every tool comes with a “startup cost.” If translating a paragraph requires a VPN, logging into a website, and entering complex prompts, this high “cognitive activation energy” will subtly make you resist. Conversely, tools like “Doubao” or WeChat’s “Yuanbao,” seamlessly integrated into your existing ecosystem, achieve almost “zero-cost activation.” The best tools are those you don’t even notice, rather than ones you have to “adapt” to.
2. Diminishing Marginal Utility: Speed Itself is Quality
For 80% of daily tasks (e.g., summarizing, simple translation), the performance difference between top-tier and medium-sized models is negligible. Chasing that extra 1% of logical rigor while enduring slower response times and hefty subscription fees is economically unsound. For information flow processing, the value of “low latency” in maintaining cognitive flow far outweighs the marginal accuracy gains from “cutting-edge parameters.”
3. Local Advantage: Ecosystem Integration Trumps Model Performance
A model operating within the WeChat ecosystem (like Yuanbao) inherently possesses an advantage in understanding official accounts and social contexts. A domestic model (like Ant’s Lingguang), when handling Chinese technical contexts and local policy nuances, often “understands” more than a flagship model located overseas. This “native feel” and data connectivity cannot be compensated for by general large models simply by adding more parameters.
Part 3: Deep Practice: Reshaping Information Acquisition with “Distributed AI”
I no longer subscribe to the notion of a single “super model.” Instead, I’ve constructed a “distributed AI matrix.” Each component has its specific role, acting like a team of assistants with distinct personalities, incrementally optimizing my information filtering system.
1. Downscaled Attack: Using Medium Models for “Rough Information Processing”
When faced with daily tasks or text interpretation, I typically opt for models in the Gemma3 27B or Qwen 30B class.
- Why are they sufficient? Models of this scale possess excellent language intuition while requiring less than 20GB of VRAM. This means a GPU costing under $300 can achieve astonishing inference speeds of 100+ tokens/s.
- Real-world experience: They act as “light cavalry” in the information stream, rapidly transforming lengthy foreign language texts or convoluted narratives into readable Chinese, completing the first layer of “impurity filtering.”
 The image above shows the daily token consumption of my deployed code on the Qwen3-30B model. Its primary uses are article summarization and bilingual translation. Using a SOTA model for these tasks would be a heavy burden in terms of both speed and cost.
The image above shows the daily token consumption of my deployed code on the Qwen3-30B model. Its primary uses are article summarization and bilingual translation. Using a SOTA model for these tasks would be a heavy burden in terms of both speed and cost.
As shown in the image below, even without extensive context, such models can precisely grasp the main points of expression (compare the first paragraph of translated meaning with the second paragraph of literal translation). This quality of “free translation” is already more than sufficient for everyday reading.

2. Real-time Companion: Breaking “Tech Anxiety” with Voice AI Interaction
In the previous Hacker Digest 018 | Frictionless Cognitive Traps, Fleeting Flashes on the Lunar Surface, I wrote: “Modern digital tools (like one-click clipping, read-it-later) foster the ‘collector’s fallacy,’ giving users the illusion that ‘hoarding is learning,’ ultimately turning note-taking systems into information graveyards.”
Faced with dense articles, many resort to “clipping” to soothe their anxiety, but uninternalized knowledge doesn’t enhance cognition. I address this by integrating Ant Group’s Lingguang AI with Doubao Voice Input Method.
- Reducing Cognitive Load: Learning new knowledge is inherently mentally exhausting. While DeepSeek is powerful, its overly detailed explanations can sometimes be intimidating. I choose Lingguang because it explains concepts “just right,” using rich media to quickly convey the core ideas without getting bogged down in minutiae.
- The Charm of Informal Input: Why emphasize voice? Keyboard input carries a certain “formality” that can disrupt reading flow. Voice input is closer to “native thought.” When you’re immersed in an article, you can casually ask a question, understand, and then continue reading—the whole process is incredibly smooth.
For example, try asking DeepSeek the same question shown below and compare its answer.

3. Deep Calibration: Using Specialized Tools for “Logical Chain Validation”
If you’re a heavy user of WeChat Official Accounts, you might scroll through a deluge of news, videos, and technical articles daily. This content isn’t always entirely factual or easy to understand. For content that requires fact-checking and deep thinking, I call upon WeChat Yuanbao. You can add Yuanbao as a contact and then forward WeChat Official Account articles or video links to it for summarization or clarification.
- Fact-Checking: WeChat Yuanbao excels at handling detailed inquiries and technical fact-checking. I demand it to cite sources for data within articles, ensuring I’m not misled. Of course, Lingguang is also very effective for fact-checking. DeepSeek, without active web search, only uses its training data. Enabling web search every time can be a burden!
- Logical Chain Validation: I often forward WeChat Official Account articles directly to “Yuanbao,” asking it to perform three tasks: summarize and organize, fact-check, and validate the logical chain. The internet today is rife with bias and marketing rhetoric. By having AI deconstruct the article’s logical structure, I can clearly discern what’s fact, what’s emotion, and what constitutes a logical leap. This “filtering” function significantly enhances the purity of the information I consume.

Part 4: Cognitive Upgrade: Evolving from “Tool User” to “Cognitive Architect”
When we stop agonizing over parameters, we effectively achieve a cognitive leap.
First, we reshape our information filtering system. In an age of information overload, acquiring information isn’t hard; filtering it is. Through a distributed AI matrix, we build a firewall unparalleled by human effort. This isn’t just an efficiency boost; it’s protection for our mental space.
Second, AI empowers us to tackle complexity. Previously, a technical paper full of equations might have deterred us. But now, with ever-ready explanatory tools, our horizons are vastly expanded. AI isn’t just providing answers; it’s training our critical thinking through continuous feedback.
Finally, pragmatism reclaims our agency over technology. Chasing trends is exhausting; building workflows is enduring. When you frequently and cheaply use these “fit-for-purpose” tools, you’re constructing your own knowledge moat. In this chain, models are mere components, while your combination logic and depth of questioning are the true engines.
Part 5: Conclusion: Returning to the Essence of Tools
We are at a technological singularity, and the iteration speed of large models is indeed dazzling. But remember, we are the masters of technology, not the subservient followers of parameters.
The most successful AI application isn’t necessarily the model that ranks first on benchmarks. It’s the “fit-for-purpose” tool that seamlessly integrates into your WeChat, your input method, your reading habits, quietly enabling you to understand articles you couldn’t before, and see through logic that was once opaque.
Stop the futile chase after SOTA, and start building your own “fit-for-purpose” workflow. After all, we don’t need an omniscient deity; we need a team of shadow assistants to help us see the world clearly.