从乌托邦到发电机:DAO 的生死轮回与 Agent-Native 协议的兴起
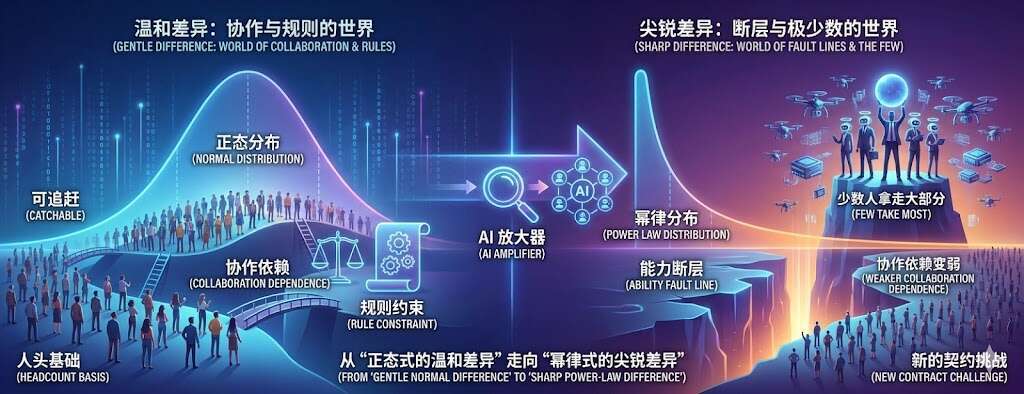
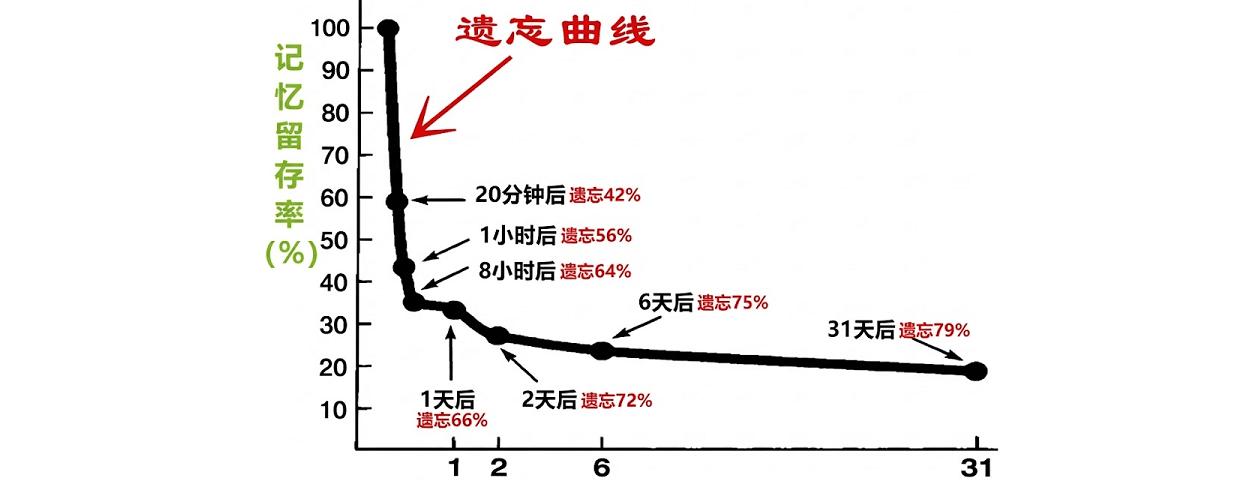
“岁末清淡无一事,竹堂寺里看梅花”。大年初一,闲散在家,最适合脑洞大开,狂想未来。 最近玩OpenClaw乐不思蜀。将其融入工作学习之余,不禁想象,如果将来人人都能指挥一个类似的AI Agent,人类社会将走往何方? 我首先会想到一个看似很小、其实很无奈的事实:AI Agent 不能开银行账户。AI Agent没有身份证,没有手机号码,银行审核一关就过不了。其根本原因是,货币是为人类社会的交换需求而生的。这句话背后藏着一个更大的矛盾。今天我们把 Agent 当成工具,用它写代码、查资料、做计划、盯交易,甚至替我们运营一个小生意。但当它真正要“自己去协作、自己去分账、自己去承担责任”时,它立刻卡在现实世界的入口:账户是谁的?合同谁来签?出了问题谁负责?钱从哪来、到哪去? 所以问题并不是“Agent 够不够聪明”,而是“Agent 有没有一套它能直接使用的经济接口”。如果没有,那么 Agent 永远只能当人的外挂,而不能成为真正的经济主体。 但是换个角度看,如果说货币是为人类社会的交换需求而生,那么区块链可能是为AI Agnet交换需求而生的。区块链不需要AI Agent拥有社会身份,只要开设一个数字钱包就可以交易。而数字化的一切,对AI Agent天然友好 。更重要的是,区块链的优势不仅仅是寻常考虑的“转账方便”,而是它天然支持智能合约,从而提供了一种更深的结构:把价格信号和执行动作放到同一个对象里。这个对象,就是 Token。 在传统世界,价格只是信号。 你看到某个资产涨了,这只告诉你“发生了什么”。至于“要不要买”“怎么做”“谁来执行”,你需要穿过银行、合同、律师、公司审批、财务拨款、审计留痕,才能把一个价格信号变成现实中的动作。价格告诉你方向,但执行靠的是制度、组织和人。 而在 Token 世界里,Token 往往不仅是“值多少钱”,它还天然携带“能做什么”。 因为 Token 可以直接连接智能合约:持有它意味着你拿到某种权限,可以触发合约执行、参与治理、领取分红、调用资源。它既是价值的载体,也是执行的钥匙。你拥有它,不只是拥有一份财富,更像拥有一份可被代码兑现的权利。 我喜欢用一个不太严谨但直观的比喻:Token 有点像“波粒二象性”。它一方面像资产那样可交易、可定价;另一方面又像权限那样持续生效、能触发动作。你拿着它,它不只是静态的“钱”,还是动态的“能力”。 一旦“价格标记”和“执行能力”合并,后面发生的事情会非常现实:交易与协作的摩擦会开始塌缩。 跨国协作、利润分配、预算拨付、激励兑现,这些在人类公司里极其昂贵、靠流程与中介维持的动作,可以被写成规则并自动运行。你不再需要找一个中心化的“信任代理人”,你把规则写进合约,让执行随价值流动。 当摩擦下降到足够低,下一击会落到更大的结构上:公司制度。 公司为什么存在? 一个经典解释来自科斯:因为市场交易有成本,所以企业内部用行政命令替代市场交易,在很多情况下更省成本。合同谈判、对账结算、信用担保、争议处理,这些都很贵,于是公司出现了,它把无数交易打包进组织,用层级和流程换取稳定。 但如果交易摩擦被系统性压低呢? 当协作可以像写代码一样精确执行,当分账可以自动完成,当信用可以被规则替代,科斯式企业的边界就会开始松动。另一种形态会浮现出来:协议驱动的全球协作网络。它不靠办公室和层级维持秩序,而靠规则和自动执行维持秩序。 这也是为什么我认为:支付方式一旦面向 Agent 被重写,生产关系也会被迫重写。支付从来不是一块小零件,它直接决定谁能参与、如何协作、怎样分配、出了问题怎么追责。换句话说,支付决定了组织协议,或者说生产关系。 说到“协议化组织”,很多人会立刻想到 DAO。 人类DAO的幻灭 DAO 是 Decentralized Autonomous Organization 的缩写,中文常译为 去中心化自治组织。 DAO 的诞生曾经带着一种强烈的理想主义。它的核心概念很简单:把“组织怎么运转”这件事尽量写成公开的规则,并用区块链上的智能合约去自动执行。资金一般放在链上的合约里,谁能动用资金、怎么分配收益、怎么通过提案与投票,都会按事先写好的规则来走。理想状态下,它不依赖某一个老板或公司来背书,而是依赖代码规则、公开账本和社区治理来形成协作与信任。 它被构想为一种“无主组织”:用代币把所有权、治理权、分红权打包;用智能合约替代官僚;用公开账本替代暗室;用社区决策替代董事会。它最吸引人的地方是:它试图把“信任”从某个具体的人或机构,转成可验证的规则。 但是现实里的 DAO,往往让人失望。 投票缓慢,争吵漫长,执行拖沓。许多项目表面去中心化,关键决策仍然依赖少数核心团队。甚至有一个人人看得见却不愿意说破的事实:如果移除了核心开发团队这种“影子内阁”,协议很多时候会变成一段无人维护的死代码。 这不是一句“人性贪婪”就能解释的。更深的原因,是治理机制对“生产力分布”的假设,可能已经过时了。 很多 DAO 的治理要么一人一票,要么一Token一票。无论哪种,都隐含一个前提:参与者的判断力与贡献差异不会大到离谱,至少可以用“多数投票”聚合意见。 但 AI 时代,人类生产力越来越像幂率分布:少数人借助工具、资本、网络效应,把产出放大到远超普通人的数量级。一个能操控一群 Agent 的极客,写出关键协议、设计关键机制、发现关键套利逻辑,其影响可能远大于成千上万只看短期价格的持币者。我此前写过一篇文章讨论这个影响:AI 繁荣的幻象:从“正态分布”到“权力幂律”,我们正处于旧秩序大崩塌的前夜) 当生产力是幂率分布,而治理仍然按“简单多数”运行,组织就会撕裂:治理权结构与真实生产力结构不匹配。创新会被拖死,或者组织回到少数人拍板,只是外面套上投票的壳。 到这里,结论似乎很悲观:DAO 不适合人类。 ...